

Let's say you have two obscenely large sets of data.
These sets of data contain information on a similar topic, such as customers. Dataset #1 might contain a high-level view of all customers of a business, while Datatset #2 contains a lifetime history of orders for a company. Unsurprisingly, the customers in Dataset #1 appear in Dataset x#2, as any business' orders are made by customers.
Welcome to Relational Databases
What we just described is the core foundation for relational databases which have been running at the core of businesses since the 1970s. Starting with familiar names like MySQL, Oracle, and Postgres, the concept of maintaining multiple -related- tables of data are the bare minimum technology stack for any company, regardless of what said company does.
While our example of Datasets #1 and #2 can be thought of as isolated tables, the process of 'joining' them (in SQL terms) or 'merging' them (in Pandas terms) is trivial. What's more, we can do far more than with JOINS (or merges) than simply combining our data into a single set.
Enter The Panda
Python happens to have an obscenely popular library for performing SQL-like logic, dubbed Pandas. If it remains unclear as to what Pandas is, just remember: Databases are basically Excel spreadsheets are basically an interface for Pandas. The technicality of that explanation may be horrendous to those who understand the differences, but the fundamental truth remains: we're dealing with information, inside of cells, on a two-dimensional grid. When you hear the next idiot spew a catchphrase like "data is the new oil", the "data" they're referring to is akin to that sick Excel sheet you made at work.
Scenario 1: Finding Mismatches in Data
This scenario actually stems from a real-life example which, sure enough, was my first encounter with Pandas. One could argue I owe much 0f my data career to a 3am Google Hangout with Snkia.
In our scenario, our company has signed up for a very expensive software product which charges by individual license. To our surprise, the number of licenses for this software totaled over 1000 seats! After giving this data a quick glance, however, it's clear that many of these employees have actually been terminated, thus resulting in an unspeakable loss in revenue.
The good news is we have another dataset called active employees (aka: employees which have not been terminated... yet). So, how do we use these two sets of data to determine which software licenses are valid? First, let's look at the types of ways we can merge data in Pandas.
Pandas Merge Terminology
Even if you're familiar with SQL JOINs, it's worth reviewing the terms Pandas uses to describe things before moving forward.
MERGE
Sets of data can be merged in a number of ways. Merges can either be used to find similarities in two DataFrames and merge associated information, or may be entirely non-destructive in the way that two sets of data are merged.
KEY
In many cases (such as the one in this tutorial) you'd likely want to merge two DataFrames based on the value of a key. A key is the authoritative column by which the DataFrames will be merged. When merging DataFrames in this way, keys will stay in tact as an identifier while the values of columns in the same row associated to that key.
This type of merge can be used when two DataFrames hold differing fields for similar rows. If DataFrame 1 contains the phone numbers of customers by name, and DataFrame 2 contains emails of a similar grouping of people, these two may be merged to create a single collection of data with all of this information.
AXIS
A parameter of pandas functions which determines whether the function should be run against a DataFrame's columns or rows. An axis of 0 determines that the action will be taken on a per-row basis, where an axis of 1 denotes column.
For example, performing a drop with axis 0 on key X will drop the row where value of a cell is equal to X.
Types of Merges
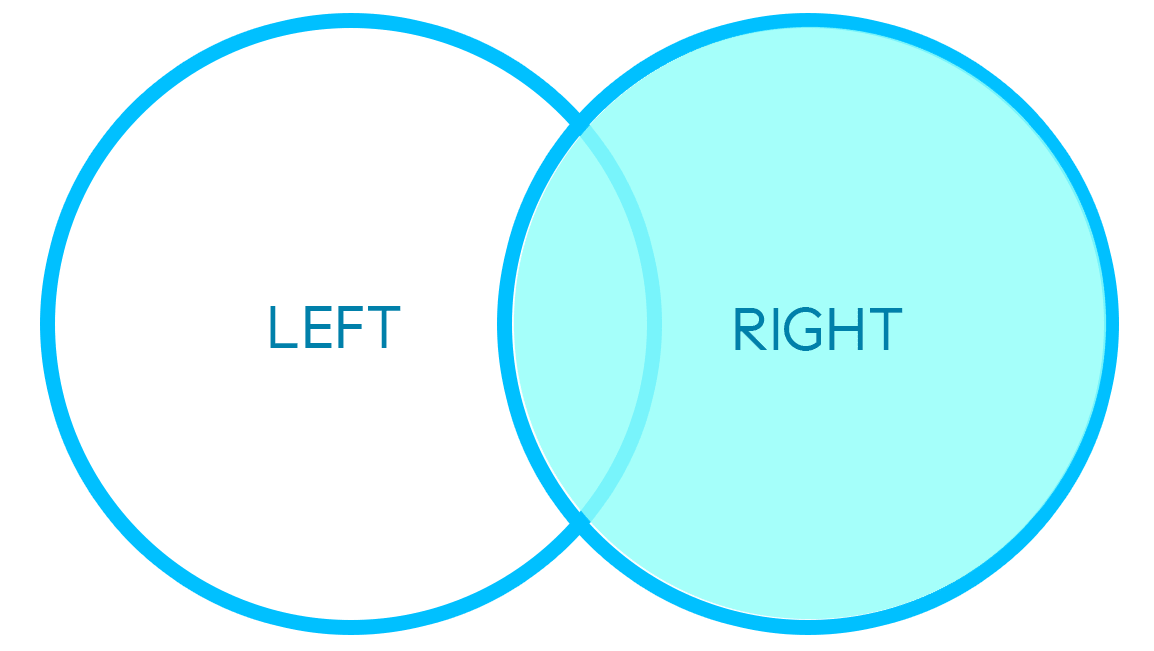
LEFT/RIGHT MERGE
An example of a left/right merge can be seen below:
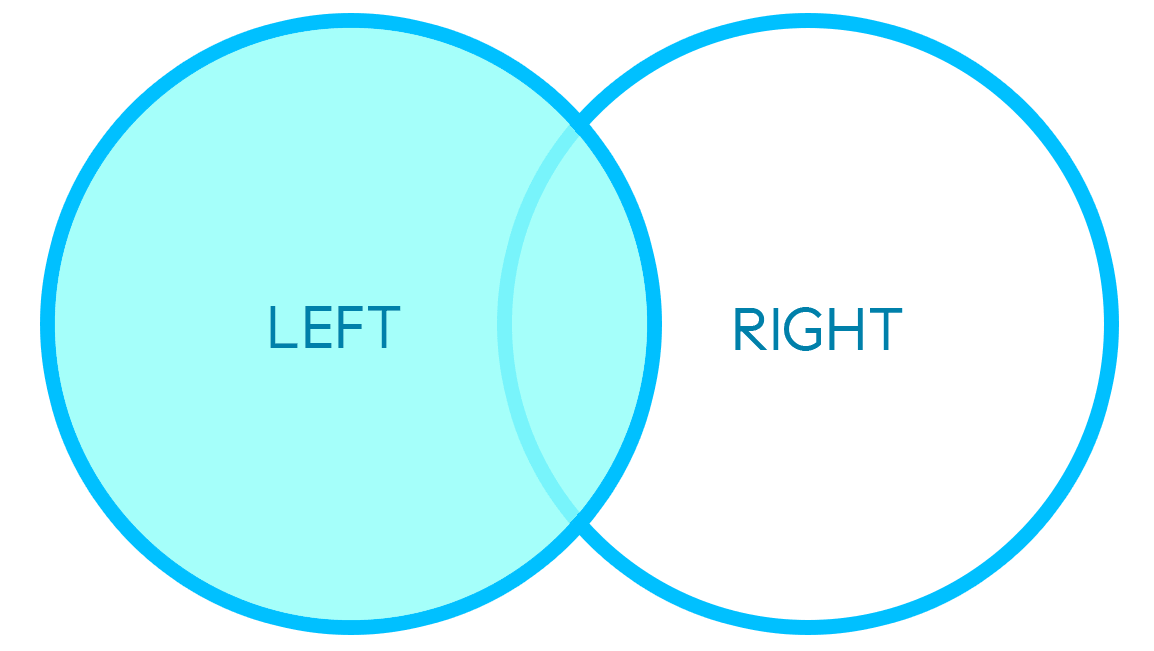
The two data frames above hold similar keys with different associated information per axis, thus the result is a combination of these two DataFrames where the keys remain intact.
"Left" or "right" refer to the left or right DataFrames above. If the keys from both DataFrames do not match 1-to-1, specifying a left/right merge determines which DataFrame's keys will be considered the authority to be preserved in the merge.
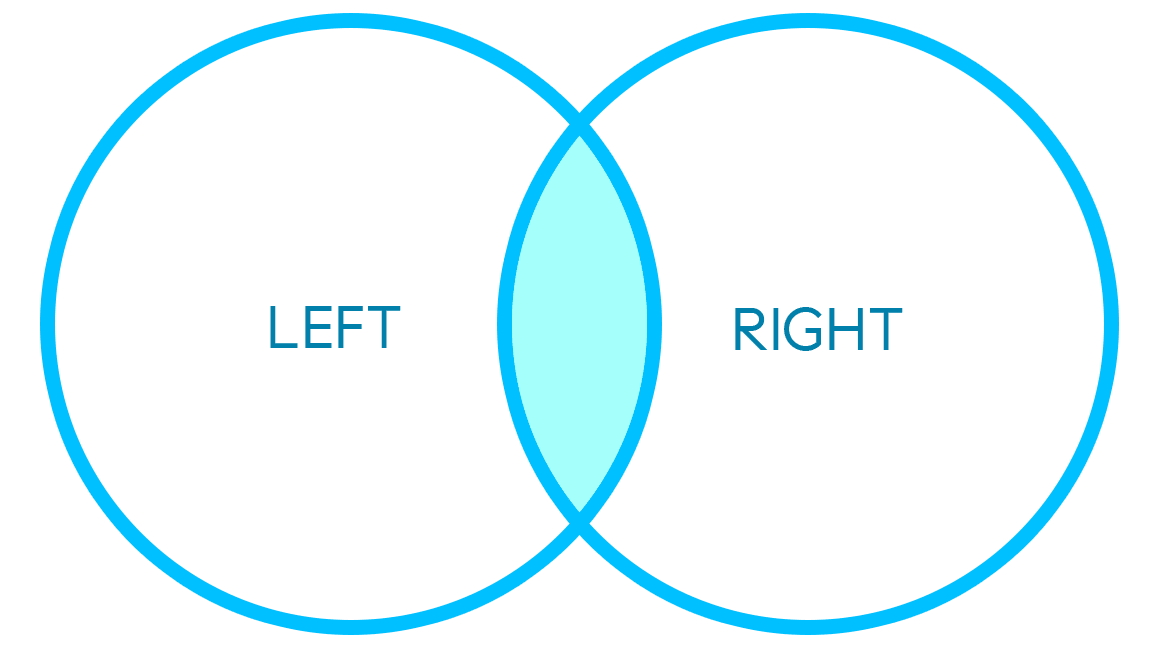
INNER MERGE
An inner merge will merge two DataFrames based on overlap of values between keys in both DataFrames:
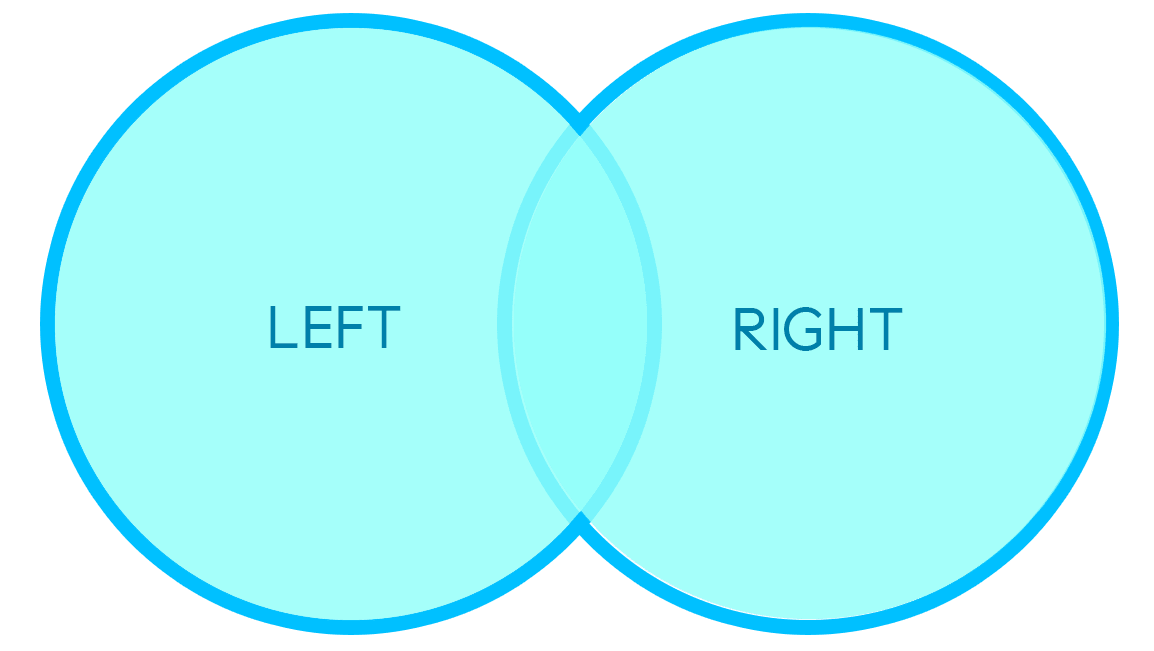
OUTER MERGE
An outer merge will preserve the most data by not dropping keys which are uncommon to both DataFrames. Keys which exist in a single DataFrame will be added to the resulting DataFrame, with empty values populated for any columns brought in by the other DataFrame:
Back to our Scenario: Merging Two DataFrames via Left Merge
Let's get it going. Enter the iPython shell. Import Pandas and read both of your CSV files:
import pandas as pd
df = pd.read_csv("csv1.csv")
df2 = pd.read_csv("csv2.csv")The above opens the CSVs as DataFrames recognizable by pandas.
Next, we'll merge the two CSV files.
How specifies the type of merge, and on specifies the column to merge by (key). The key must be present in both DataFrames.
For the purpose of this exercise we'll be merging left, as that is the CSV which contains the keys we'd like to maintain.
...
mergedDF = df2.merge(df, how=“left”, on="email")
print(mergedDF)
This should return a dataset of all common rows, with columns from both CSVs included in the merge.
Scenario 3: Missing Data
Before we go, let's toss in another scenario for good measure.
This time around we have two datasets which should actually probably be a single dataset. Dataset #1 contains all customers once again, but for some reason, Dataset #1 contains email address where set Dataset #2 does not. Similarly, Dataset #2 contains addresses which are missing in Dataset #1. We assume there is no reason to keep these sets of data isolated other than human error.
In the case where we are confident that employees exist in both datasets but contain different information, performing an inner merge will join these two sets by a key such as customer ID or email. If all goes well, the final dataset should equal the same number of rows found in both Datasets #1 and #2.
For more on merging, check out the official Pandas documentation here.



