

Something we haven't done just yet on this site is walking through the humble process of creating data pipelines: the art of taking a bunch of data, changing said data, and putting it somewhere else. It's kind of a weird thing to be into, hence why the MoMA has been rejecting my submissions of Github repositories. Don't worry; I'll keep at it.
Something you don't see every day are people sharing their pipelines, which is understandable. Presumably, the other people who do this kind of stuff do it for work; nobody is happily building stupid pipelines in their free time begging to be open sourced. Except me.
We've recently revamped our projects page* to include a public-facing Kanban board using GraphQL. To achieve this, we need to extract JIRA data from the JIRA Cloud REST API and place it securely in our database.
Structuring our Pipeline
An ETL pipeline which is considered 'well-structured' is in the eyes of the beholder. There are a million different ways to pull and mess with data, so there isn't a "template" for building these things out. In my case, the structure of my script just so happened to end up as three modules: one for extracting, one for loading, and one for transforming. This was unplanned, but it's a good sign when our app matches our mindset. Here's the breakdown:
jira-database-etl
├── application
│ ├── __init__.py
│ ├── db.py
│ ├── jirafetch.py
│ └── transform.py
├── assets
│ └── jira-serverless-import.jpg
├── logs
│ └── errors.log
├── main.py
├── config.py
├── requirements.txt
├── LICENSE
├── MANIFEST.in
├── Pipfile
├── Pipfile.lock
├── README.md
├── setup.cfg
└── setup.pymain.py is our application entry point which simply initializes the application package. Within application, the logic of our script is split into three parts:
- jirafetch.py: Grabs raw JSON data for JIRA issues via the JIRA Cloud REST API. Our script determines which tickets to pull by a JQL query we provide.
- transform.py: Transforms our issue JSON data into a Pandas DataFrame which can be easily uploaded to a SQL database. Much of this process involves cleaning the JSON data, and accounting for instance where fields might come back empty.
- db.py: Loads our cleaned data into a SQL database.
Our Entry Point
Our application module is initiated by our init file. Our main() function simply initializes and steps through the three phases of our script: extracting, transforming, and loading. Each function below represents the corresponding phase, respectively:
import logging
from config import Config
from .jirafetch import FetchJiraIssues
from .transform import TransformData
from .db import Database
def main():
"""Application Entry Point."""
logger = logging.basicConfig(filename='logs/errors.log',
filemode='w',
format='%(name)s - %(levelname)s - %(message)s',
level=logging.ERROR)
issues = fetch_raw_jira_issues()
issues = clean_jira_issues(issues)
upload = upload_issues(issues)
print(upload)
def fetch_raw_jira_issues():
"""Fetch raw JSON data for JIRA issues."""
print('Fetching issues from JIRA...')
jira = FetchJiraIssues()
issues_json = jira.fetch_all_results()
return issues_json
def clean_jira_issues(issues):
"""Clean data and create pandas DataFrame."""
print('Transforming JIRA issues to tabular data...')
transform = TransformData(issues)
issues_df = transform.construct_dataframe()
return issues_df
def upload_issues(issues):
"""Upload issues table to SQL database."""
print("Preparing database upload...")
db = Database(Config)
upload = db.upload_dataframe(issues)
return upload
First, we extract raw JSON data from JIRA, which is handled in the fetch_raw_jira_issues() function. Here we initialize our "fetch" class, and begin the process of pulling data.
Extracting Our Data
Before digging into jirafetch.py, its essential we become familiar with the data we're about to pull. Firstly, JIRA's REST API returns paginated results which max out at 100 results per page. This means we'll have to loop through the pages recursively until all results are loaded.
Next, let's look at an example of a single JIRA issue JSON object returned by the API:
{
"expand": "names,schema",
"startAt": 0,
"maxResults": 1,
"total": 888,
"issues": [
{
"expand": "operations,versionedRepresentations,editmeta,changelog,renderedFields",
"id": "11718",
"self": "https://hackersandslackers.atlassian.net/rest/api/3/issue/11718",
"key": "HACK-756",
"fields": {
"issuetype": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/issuetype/10014",
"id": "10014",
"description": "Placeholder item for \"holy shit this is going to be a lot of work\"",
"iconUrl": "https://hackersandslackers.atlassian.net/secure/viewavatar?size=xsmall&avatarId=10311&avatarType=issuetype",
"name": "Major Functionality",
"subtask": false,
"avatarId": 10311
},
"customfield_10070": null,
"customfield_10071": null,
"customfield_10073": null,
"customfield_10074": null,
"customfield_10075": null,
"project": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/project/10015",
"id": "10015",
"key": "HACK",
"name": "Hackers and Slackers",
"projectTypeKey": "software",
"avatarUrls": {
"48x48": "https://hackersandslackers.atlassian.net/secure/projectavatar?pid=10015&avatarId=10535",
"24x24": "https://hackersandslackers.atlassian.net/secure/projectavatar?size=small&pid=10015&avatarId=10535",
"16x16": "https://hackersandslackers.atlassian.net/secure/projectavatar?size=xsmall&pid=10015&avatarId=10535",
"32x32": "https://hackersandslackers.atlassian.net/secure/projectavatar?size=medium&pid=10015&avatarId=10535"
}
},
"fixVersions": [],
"resolution": null,
"resolutiondate": null,
"workratio": -1,
"lastViewed": "2019-03-24T02:01:31.355-0400",
"watches": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/issue/HACK-756/watchers",
"watchCount": 1,
"isWatching": true
},
"created": "2019-02-03T00:47:36.677-0500",
"customfield_10062": null,
"customfield_10063": null,
"customfield_10064": null,
"customfield_10065": null,
"customfield_10066": null,
"priority": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/priority/2",
"iconUrl": "https://hackersandslackers.atlassian.net/images/icons/priorities/high.svg",
"name": "High",
"id": "2"
},
"customfield_10067": null,
"customfield_10068": null,
"customfield_10069": [],
"labels": [],
"versions": [],
"issuelinks": [],
"assignee": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/user?accountId=557058%3A713aac6d-44ef-416d-9a1d-3e524a5c4dc8",
"name": "bro",
"key": "admin",
"accountId": "557058:713aac6d-44ef-416d-9a1d-3e524a5c4dc8",
"emailAddress": "toddbirchard@gmail.com",
"avatarUrls": {
"48x48": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=48&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D48%26noRedirect%3Dtrue",
"24x24": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=24&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D24%26noRedirect%3Dtrue",
"16x16": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=16&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D16%26noRedirect%3Dtrue",
"32x32": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=32&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D32%26noRedirect%3Dtrue"
},
"displayName": "Todd Birchard",
"active": true,
"timeZone": "America/New_York",
"accountType": "atlassian"
},
"updated": "2019-03-24T02:01:30.724-0400",
"status": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/status/10004",
"description": "",
"iconUrl": "https://hackersandslackers.atlassian.net/",
"name": "To Do",
"id": "10004",
"statusCategory": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/statuscategory/2",
"id": 2,
"key": "new",
"colorName": "blue-gray",
"name": "To Do"
}
},
"components": [],
"description": {
"version": 1,
"type": "doc",
"content": [
{
"type": "paragraph",
"content": [
{
"type": "text",
"text": "https://mailchimp.com/help/share-your-blog-posts-with-mailchimp/",
"marks": [
{
"type": "link",
"attrs": {
"href": "https://mailchimp.com/help/share-your-blog-posts-with-mailchimp/"
}
}
]
}
]
}
]
},
"customfield_10010": null,
"customfield_10011": "0|i0064j:i",
"customfield_10012": null,
"customfield_10013": null,
"security": null,
"customfield_10008": "HACK-143",
"customfield_10009": {
"hasEpicLinkFieldDependency": false,
"showField": false,
"nonEditableReason": {
"reason": "PLUGIN_LICENSE_ERROR",
"message": "Portfolio for Jira must be licensed for the Parent Link to be available."
}
},
"summary": "Automate newsletter",
"creator": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/user?accountId=557058%3A713aac6d-44ef-416d-9a1d-3e524a5c4dc8",
"name": "bro",
"key": "admin",
"accountId": "557058:713aac6d-44ef-416d-9a1d-3e524a5c4dc8",
"emailAddress": "toddbirchard@gmail.com",
"avatarUrls": {
"48x48": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=48&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D48%26noRedirect%3Dtrue",
"24x24": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=24&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D24%26noRedirect%3Dtrue",
"16x16": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=16&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D16%26noRedirect%3Dtrue",
"32x32": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=32&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D32%26noRedirect%3Dtrue"
},
"displayName": "Todd Birchard",
"active": true,
"timeZone": "America/New_York",
"accountType": "atlassian"
},
"subtasks": [],
"reporter": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/user?accountId=557058%3A713aac6d-44ef-416d-9a1d-3e524a5c4dc8",
"name": "bro",
"key": "admin",
"accountId": "557058:713aac6d-44ef-416d-9a1d-3e524a5c4dc8",
"emailAddress": "toddbirchard@gmail.com",
"avatarUrls": {
"48x48": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=48&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D48%26noRedirect%3Dtrue",
"24x24": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=24&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D24%26noRedirect%3Dtrue",
"16x16": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=16&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D16%26noRedirect%3Dtrue",
"32x32": "https://avatar-cdn.atlassian.com/9eb3868db428fb602e03b3059608199b?s=32&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9eb3868db428fb602e03b3059608199b%3Fd%3Dmm%26s%3D32%26noRedirect%3Dtrue"
},
"displayName": "Todd Birchard",
"active": true,
"timeZone": "America/New_York",
"accountType": "atlassian"
},
"customfield_10000": "{}",
"customfield_10001": null,
"customfield_10004": null,
"environment": null,
"duedate": null,
"votes": {
"self": "https://hackersandslackers.atlassian.net/rest/api/3/issue/HACK-756/votes",
"votes": 0,
"hasVoted": false
}
}
}
]
}Whoa, mama! That's a ton of BS for a single issue. You can see now why we'd want to transform this data before importing ten million fields into any database. Make note of these important fields:
startAt: An integer which tells us which issue number the paginated results start at.maxResults: Denotes the maximum number of results per page (this maxes out at 100 issues).total: The total number of issues across all pages.issues: A list of objects which contain the information for exactly one JIRA issue per object
Great. So the purpose of jirafetch.py will essentially consist of creating a list of all 888 issues (in my case), and passing that off for transformation. Check it the source I came up with:
import math
import requests
from config import Config
class FetchJiraIssues:
"""Fetch all public-facing issues from JIRA instance.
1. Retrieve all values from env vars.
2. Construct request against JIRA REST API.
3. Fetch paginated issues via recursion.
4. Pass final JSON to be transformed into a DataFrame.
"""
def __init__(self):
self.jira_username = Config.jira_username
self.jira_password = Config.jira_password
self.jira_endpoint = Config.jira_endpoint
self.jira_jql = Config.jira_jql
self.results_per_page = 100
self.num_issues = self.get_total_number_of_issues()
def get_total_number_of_issues(self):
"""Gets the total number of results to retrieve."""
params = {
"jql": self.jira_jql,
"maxResults": 0,
"startAt": 0}
req = requests.get(self.jira_endpoint,
headers={"Accept": "application/json"},
params=params,
auth=(self.jira_username, self.jira_password))
return req.json()['total']
def fetch_all_results(self):
"""Retrieve all JIRA issues."""
issue_arr = []
def fetch_single_page(total_results):
"""Fetch one page of results, determine if more pages exist."""
params = {
"jql": self.jira_jql,
"maxResults": self.results_per_page,
"startAt": len(issue_arr)}
req = requests.get(self.jira_endpoint,
headers={"Accept": "application/json"},
params=params,
auth=(self.jira_username, self.jira_password))
response = req.json()
issues = response['issues']
issues_so_far = len(issue_arr) + self.results_per_page
if issues_so_far > self.num_issues:
issues_so_far = self.num_issues
print(f'Fetched {issues_so_far} out of {self.num_issues} total issues.')
issue_arr.extend(issues)
# Check if additional pages of results exist.
count = math.ceil(self.num_issues/self.results_per_page)
for x in range(0, count):
fetch_single_page(self.num_issues)
return issue_arr
This class has two methods:
get_total_number_of_issues: All this does is essentially pull the number of issues (888) from the REST API. We'll use this number in our next function to check if additional pages exist.fetch_all_results: This is where things start getting fun. fetch_all_results is a @classmethod which contains a function within itself. fetch_all_results gets the total number of JIRA issues and then calls upon child function fetch_single_page to pull JIRA issue JSON objects and dump them into a list calledissue_arruntil all issues are accounted for.
Because we have 888 issues and can retrieve 100 issues at a time, our function fetch_single_page should run 9 times. And it does!
Transforming Our Data
So now we have a list of 888 messy JIRA issues. The scope of transform.py should be to pull out only the data we want, and make sure that data is clean:
import json
from pandas.io.json import json_normalize
from datetime import datetime
from collections import defaultdict
class TransformData:
"""Build JIRA issue DataFrame from raw JSON respsone."""
def __init__(self, issues_json):
self.issue_count = 0
self.issues_json = issues_json
def construct_dataframe(self):
"""Make DataFrame out of data received from JIRA API."""
issue_list = [self.make_issue_body(issue) for issue in self.issues_json]
issue_json_list = [self.dict_to_json_string(issue) for issue in issue_list]
jira_issues_df = json_normalize(issue_json_list)
return jira_issues_df
def dict_to_json_string(self, issue_dict):
"""Convert dict to JSON to string."""
issue_json_string = json.dumps(issue_dict)
issue_json = json.loads(issue_json_string)
return issue_json
def make_issue_body(self, issue):
"""Create a JSON body for each ticket."""
updated_date = datetime.strptime(issue['fields']['updated'], "%Y-%m-%dT%H:%M:%S.%f%z")
created_date = datetime.strptime(issue['fields']['created'], "%Y-%m-%dT%H:%M:%S.%f%z")
body = defaultdict(None)
body['id'] = self.issue_count
body['key'] = issue.get('key')
body['summary'] = issue.get('fields', {}).get('summary')
body['status'] = issue.get('fields', {}).get('status', {}).get('name', {}).replace(' ', '')
body['assignee_name'] = issue.get('fields', {}).get('assignee', {}).get('displayName')
body['assignee_url'] = issue.get('fields', {}).get('assignee', {}).get('avatarUrls').get('48x48')
body['priority_url'] = issue.get('fields', {}).get('priority', {}).get('iconUrl', {})
body['priority_rank'] = issue.get('fields', {}).get('priority', {}).get('id', {})
body['issuetype_name'] = issue.get('fields', {}).get('issuetype', {}).get('name', {})
body['issuetype_icon'] = issue.get('fields', {}).get('issuetype', {}).get('iconUrl', {})
body['project'] = issue.get('fields', {}).get('project', {}).get('name', {})
body['epic_link'] = issue.get('fields', {}).get('customfield_10008')
body['updated'] = int(datetime.timestamp(updated_date))
body['created'] = int(datetime.timestamp(created_date))
self.issue_count += 1
return body
Again, let's see the methods at work:
construct_dataframe: The main function we invoke to build our DataFrame (mostly just calls other methods). Once all transformations are completed, creates a DataFrame called jira_df by using the Pandas json_normalize() method.make_issue_body: Creates a new dictionary per singular JIRA issue. Extracts only the fields we want to be imported into our database. We need to access each key of our JIRA JSON to pass into this dict, but what if some issues don't have the key we're looking for? This would normally result in a KeyError, which breaks our script entirely. To avoid this we use Python's defaultdict data structure, which populates missing key values with a default value (likeNone) instead of erroring out.dict_to_json_string: We now have a clean dictionary suitable for a database! Our last step in preparing this data is to convert it to a tabular format, such as a Pandas DataFrame.
Loading Our Data
And now for the final step! Thanks to the joyful marriage of Pandas and SQLAlchemy, turning DataFrames into SQL tables is super simple. We never make things simple, though.
from sqlalchemy import create_engine, MetaData, text
from sqlalchemy.types import Integer, Text, TIMESTAMP, String
import pandas as pd
class Database:
"""Merge Epic metadata and upload JIRA issues.
1. Merge Epic metadata by fetching an existing table.
2. Explicitly set data types for all columns found in jira_issues_df.
2. Create a new table from the final jira_issues_df.
"""
def __init__(self, Config):
self.db_uri = Config.db_uri
self.db_jira_table = Config.db_jira_table
self.db_epic_table = Config.db_epic_table
self.db_schema = Config.db_schema
self.meta = MetaData(schema=self.db_schema)
self.engine = create_engine(self.db_uri,
connect_args={'sslmode': 'require'},
echo=False)
def truncate_table(self):
"""Clear table of data."""
sql = text(f'TRUNCATE TABLE \"{self.db_schema}\".\"{self.db_jira_table}\"')
self.engine.execute(sql)
def merge_epic_metadata(self, jira_issues_df):
"""Merge epic metadata from existing SQL table."""
self.truncate_table()
epics_df = pd.read_sql_table(self.db_epic_table,
self.engine,
schema=self.db_schema)
jira_issues_df = pd.merge(jira_issues_df,
epics_df[['epic_link', 'epic_name', 'epic_color']],
how='left',
on='epic_link',
copy=False)
return jira_issues_df
def upload_dataframe(self, jira_issues_df):
"""Upload JIRA DataFrame to database."""
jira_issues_df = self.merge_epic_metadata(jira_issues_df)
jira_issues_df.to_sql(self.db_jira_table,
self.engine,
if_exists='replace',
chunksize=500,
index=False,
schema=self.db_schema,
dtype={"assignee": String(30),
"assignee_url": Text,
"epic_link": String(50),
"issuetype_name": String(50),
"issuetype_icon": Text,
"key": String(10),
"priority_name": String(30),
"priority_rank": Integer,
"priority_url": Text,
"project": String(50),
"status": String(30),
"summary": Text,
"updated": Integer,
"created": Integer,
"epic_color": String(20),
"epic_name": String(50)})
success_message = f'Uploaded {len(jira_issues_df)} rows to {self.db_jira_table} table.'
return success_message
merge_epic_metadata: Due to the nature of the JIRA REST API, some metadata is missing per issue. If you're interested, the data missing revolves around Epics: JIRA's REST API does not include the Epic Name or Epic Color fields of linked epics.upload_dataframe: Uses Panda's to_sql() method to upload our DataFrame into a SQL table (our target happens to be PostgreSQL, so we pass schema here). To make things explicit, we set the data type of every column on upload.
Well, let's see how we made out!
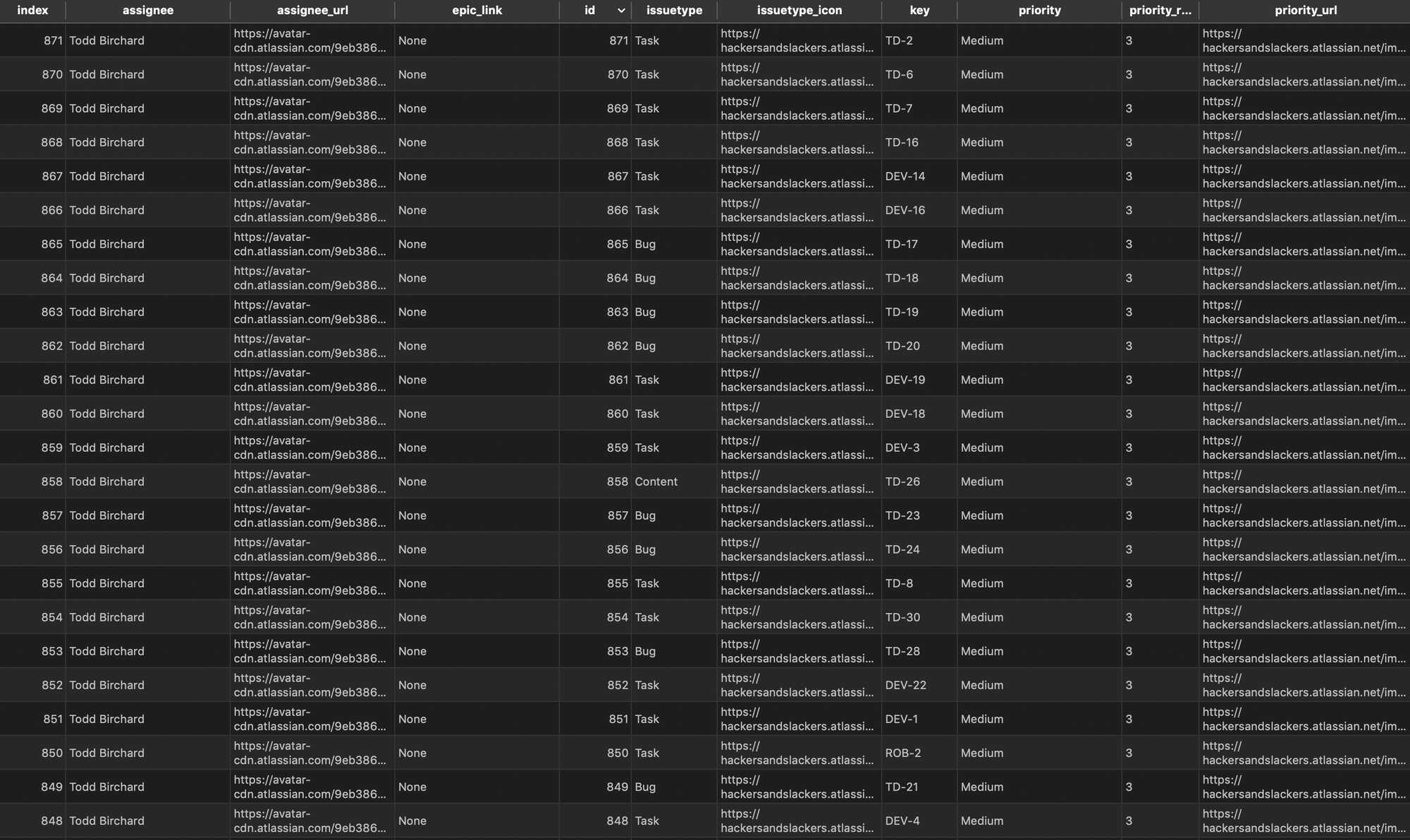
Whoaaa nelly, we did it! With our data clean, we can now build something useful! Here's what I built:
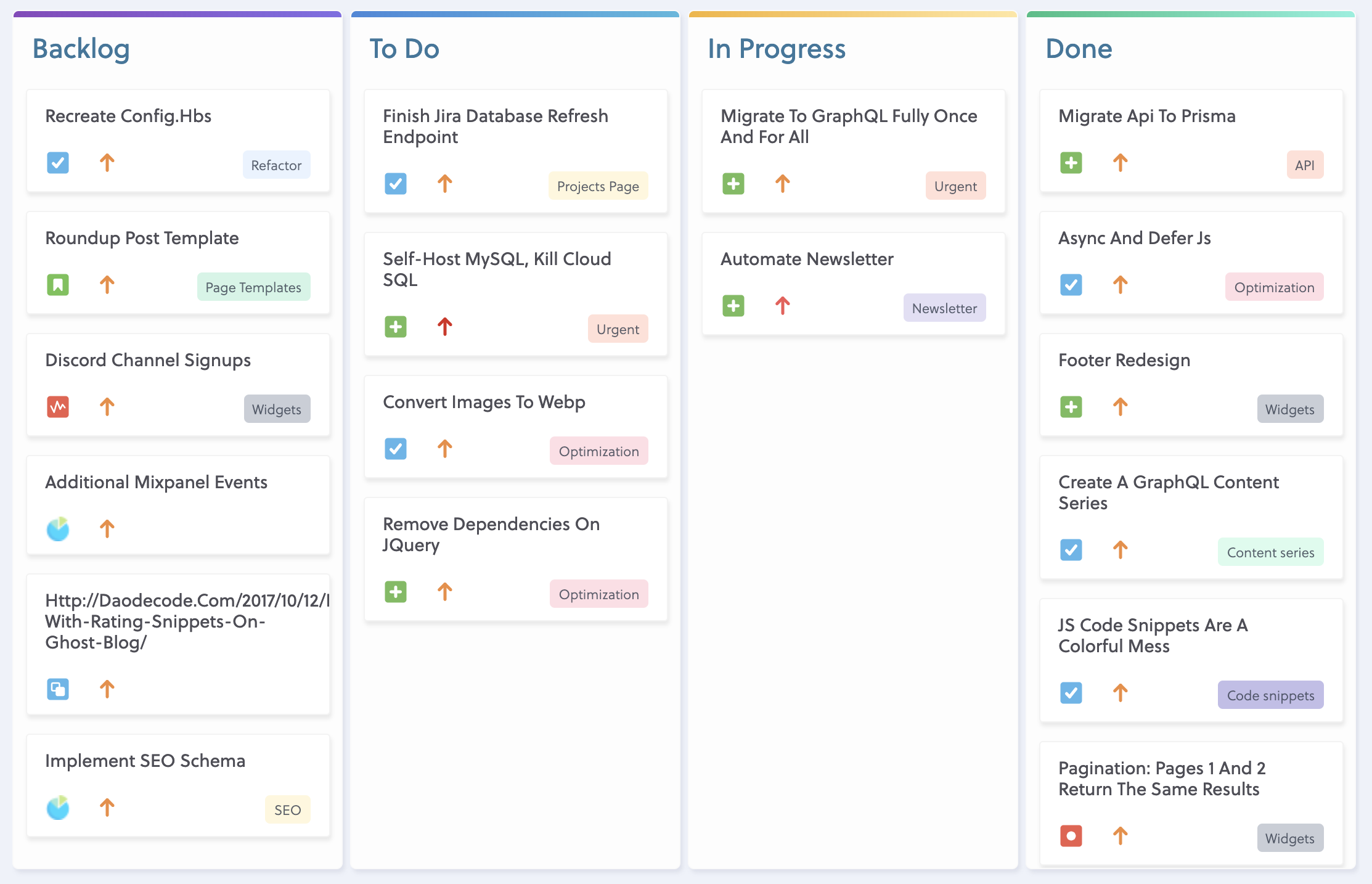
There we have it: a pipeline that takes a bunch of messy data, cleans it, and puts it somewhere else for proper use.
If you're interested in how we created the frontend for our Kanban board, check out our series on building features with GraphQL. For the source code, check out the Github repository.



