

Humanity will forever be in debt to Silicon Valley for its innovative history of recklessly monetizing human life, spewing arrogant claims of bettering the world, and disrupting the oppressive intuition of face-to-face interaction.
Despite our love for these pioneers of change, it's hard not to enjoy the show when the titans of FAANG attempt to destroy each other. 10 years ago, Microsoft nearly decimated Google with a sophisticated secret weapon called Bing: a shitty search engine that the majority of the world would assume was google.com by virtue of opening Internet Explorer. Google struck back hard with Chrome: a product so successful at not-being-Internet-Explorer that it has given Google power to shape the internet itself. Given their history, it's hard to imagine these war machines putting down their guns and settling their differences. Or at least it was until AWS happened.
The term multi-cloud is yet another tech buzzword most of us have grown numb to, as everything on earth slowly becomes engulfed in AI Blockchain VR Cloud As-A-Services. If we pay attention, it's clear "multi-cloud" is a term used exclusively by two corporations of the three aforementioned corporations (read: the only companies with a significant non-AWS cloud offering). It's no coincidence that Amazon banned the usage of the term "multi-cloud" from all internal communications.
"Multi-cloud" implies that there is a benefit to paying bills to not one, but multiple cloud providers; presumably insinuating that there are products on Google Cloud and Azure which are better than AWS' offerings. It's a narrative intended to bore its way into the skulls of technical decision-makers, but occasionally these companies have a point. For Google, one such point is BigQuery: a data warehouse with cost efficiency and usability that surpasses Redshift by a margin so absurdly large that getting gouged by double the number of cloud providers is actually a better deal.
Under The Hood
BigQuery evolved from one of Google's internal tools called Dremel: a powerful tool able to execute queries against data from all of Google's products (YouTube, Gmail, Google docs, and so forth). Dremel/BigQuery's architecture is a network of tens of thousands of Google servers accessible by all GCP users, essentially serving as a single shared service on a massive scale. Instead of worrying about how to scale data warehouse cluster horizontally, BigQuery leverages the Google Cloud network to determine how your data is partitioned across nodes presumably shared by any number of other cloud customers. This provides us with two major benefits:
- Price: BigQuery charges by usage, determined by the size of each query. This makes BigQuery a significantly cheaper data warehouse option for smaller shops which don't utilize their clusters 24/7.
- Time: It's hard to express what a pain in the ass it is to maintain, optimize, and "fine tune" a Redshift instance. We scratch the surface of the details in another post, but I'd recommend avoiding it unless you're a masochist. Not only are Redshift instances more expensive than the hardware they run on, but it's up to you to ensure data is being partitioned correctly, sweating over "distribution styles" in the endless battle for passable performance. As a general rule of thumb, if "fine tuning" is a primary attribute of your job description, your life might suck.
In my life's list of priorities, time and money are near the top of that list.
BigQuery Python SDK
GCP provides powerful developer SDKs for each of its services, and BigQuery is no exception. We'll be using BigQuery's Python SDK in tandem with the Google Cloud Storage Python SDK to import raw CSV into a new BigQuery table. To follow along, it's recommended that you have a basic knowledge of the following:
- Enabling services in Google Cloud (BigQuery here and Cloud Storage here).
- Generating Service Account keys for Google Clouds APIs (reference here)
- The concept of environment variables and how to use them in Python.
If you find yourself getting lost at any point, the source code for this tutorial is on Github here:
 hackersandslackers
hackersandslackersSetting Up
As mentioned, we need to generate a service account key in Google Cloud Console with access to BigQuery and Cloud Storage. Download this JSON file and store it in your project's root directory. Don't commit this file to Github or share it with anybody.
We also need some data. I'll be using a dataset of fake employees; part of this exercise is to demonstrate BigQuery's ability to infer datatypes, so I intentionally picked data with a fairly diverse collection of column datatypes:
| id | initiated_date | hire_date | first_name | last_name | title | |
|---|---|---|---|---|---|---|
| 100035435 | 2015-12-11T09:16:20.722-08:00 | 3/22/67 | GretchenRMorrow@jourrapide.com | Gretchen | Morrow | Power plant operator |
| 100056435 | 2015-12-15T10:11:24.604-08:00 | 6/22/99 | ElizabethLSnow@armyspy.com | Elizabeth | Snow | Oxygen therapist |
| 100037955 | 2015-12-16T14:31:32.765-08:00 | 5/31/74 | AlbertMPeterson@einrot.com | Albert | Peterson | Psychologist |
| 100035435 | 2016-01-20T11:15:47.249-08:00 | 9/9/69 | JohnMLynch@dayrep.com | John | Lynch | Environmental hydrologist |
| 100057657 | 2016-01-21T12:45:38.261-08:00 | 4/9/83 | TheresaJCahoon@teleworm.us | Theresa | Cahoon | Personal chef |
| 100056747 | 2016-02-01T11:25:39.317-08:00 | 6/26/98 | KennethHPayne@dayrep.com | Kenneth | Payne | Central office operator |
| 100035435 | 2016-02-01T11:28:11.953-08:00 | 4/16/82 | LeifTSpeights@fleckens.hu | Leif | Speights | Staff development director |
| 100035435 | 2016-02-01T12:21:01.756-08:00 | 8/6/80 | JamesSRobinson@teleworm.us | James | Robinson | Scheduling clerk |
| 100074688 | 2016-02-01T13:29:19.147-08:00 | 12/14/74 | AnnaDMoberly@jourrapide.com | Anna | Moberly | Playwright |
| 100665778 | 2016-02-04T14:40:05.223-08:00 | 9/13/66 | MarjorieBCrawford@armyspy.com | Marjorie | Crawford | Court, municipal, and license clerk |
| 100876876 | 2016-02-24T12:39:25.872-08:00 | 12/19/67 | LyleCHackett@fleckens.hu | Lyle | Hackett | Airframe mechanic |
| 100658565 | 2016-02-29T15:52:12.933-08:00 | 11/17/83 | MaryJDensmore@jourrapide.com | Mary | Densmore | Employer relations representative |
While there are now a number of ways to get data into a BigQuery table, the preferred method we'll use is importing data through Google Cloud Storage. With all that in mind, spin up a Python environment and install the following packages:
$ pip3 install google-cloud-storage google-cloud-bigquery python-dotenvInstall requirements
Configuration
With your service key JSON in your project folder, you'll also need to set an environment variable called GOOGLE_APPLICATION_CREDENTIALS which should equal the file path to your key. If you have trouble getting set up, check out the Python SDK set up instructions.
Our script will need to be configured to work with our Google Cloud account, which we'll do in config.py. We need to configure the two GCP services we're utilizing in our script: Google Cloud Storage and Google BigQuery.
"""Google Cloud project configuration."""
from os import getenv, path
from dotenv import load_dotenv
# Load variables from .env
basedir = path.abspath(path.dirname(__file__))
load_dotenv(path.join(basedir, ".env"))
# GCP Project
GCP_PROJECT_ID: str = getenv("GCP_PROJECT_ID")
# Google Cloud Storage
GCP_BUCKET_NAME: str = getenv("GCP_BUCKET_NAME")
# Google BigQuery
GCP_BIGQUERY_TABLE_ID: str = getenv("GCP_BIGQUERY_TABLE_ID")
GCP_BIGQUERY_DATASET_ID: str = getenv("GCP_BIGQUERY_DATASET_ID")
GCP_BIGQUERY_FULL_TABLE_ID: str = (
f"{GCP_PROJECT_ID}.{GCP_BIGQUERY_DATASET_ID}.{GCP_BIGQUERY_TABLE_ID}"
)
# Data
LOCAL_CSV_FILEPATH: str = f"{basedir}/data/employees.csv"
REMOTE_CSV_DESTINATION: str = "datasets/employees.csv"
config.py
A quick breakdown of what we're working with here:
GCP_PROJECT_ID: The ID of your Google Cloud project (found basically anywhere, including the URL of your console).GCP_BUCKET_NAME: The name of a Google Cloud Storage bucket which will serve as the destination for our CSV upload.GCP_BIGQUERY_TABLE_ID: Desired table name of our Google BigQuery table.GCP_BIGQUERY_DATASET_ID: BigQuery dataset destination to store our table under.GCP_BIGQUERY_FULL_TABLE_ID: Similarly to how SQL tables can be referenced across databases by following the dot notation of DATABASE_NAME.TABLE_NAME, BigQuery follows the convention of identifying tables by drilling down from the top (project id) to the bottom (table ID). We'll refer to this as the "full" table ID as it gives us a convenient path to our table, but should not be confused with the actual table ID, which is the simple table name we set earlier.LOCAL_CSV_FILEPATH: File path to a local CSV containing data we'd like to upload.REMOTE_CSV_DESTINATION: Remote file path our CSV will be saved to in our Google Cloud Storage bucket.
Upload Data to Google Cloud Storage
The most effortless way to create a new BigQuery table from raw data is via a file hosted on Google Cloud Storage We've covered working in GCS in detail in a past tutorial, so we'll blow through this quick.
Starting a GCS client is easy:
"""Instantiate Google Cloud Storage Client."""
from google.cloud import storage
from config import GCP_PROJECT_ID
gcs = storage.Client(GCP_PROJECT_ID)google_cloud_storage.py
Our first function is going to take a CSV we've stored locally and upload it to a bucket:
"""Upload file to Google Cloud Storage."""
from typing import Optional
from google.cloud.storage.blob import Blob
from .clients import LOGGER, gcs
def upload_csv_data(
csv_filepath: str, bucket_name: str, blob_destination: str
) -> Optional[Blob]:
"""
Upload a CSV to Google Cloud Storage.
:param csv_filepath: Filepath to local CSV to create BigQuery from.
:type csv_filepath: str
:param bucket_name: Name of Google Cloud Storage.
:type bucket_name: str
:param blob_destination: Remote path to store new blob.
:type blob_destination: str
:returns: Blob
"""
try:
bucket = gcs.get_bucket(bucket_name)
blob = bucket.blob(blob_destination)
blob.upload_from_filename(csv_filepath)
LOGGER.success(
f"Successfully uploaded `{csv_filepath}` to `{blob_destination}`."
)
return blob
except Exception as e:
LOGGER.error(f"Unexpected error while uploading CSV: {e}")storage.py
Successful execution of the above should result in a local file being uploaded to your specified Google Cloud Storage bucket. If all went well, you should see a similar success message:
Successfully uploaded `/bigquery-python-tutorial/data/employees.csv` to `datasets/employees.csv`.The output of a successful CSV upload
Inserting Data from Cloud Storage to BigQuery
With our data uploaded to Google Cloud Storage, we can now import our data into BigQuery. Similar to how we created a "client" for Google Cloud Storage, we're going to do the same for BigQuery:
"""Instantiate Google BigQuery Client."""
from google.cloud import bigquery as google_bigquery
from config import GCP_PROJECT_ID
gbq = google_bigquery.Client(project=GCP_PROJECT_ID)
google_bigquery.py
Create Tables from CSVs
We're going to define a function to generate a BigQuery table by inserting data parsed from the CSV we uploaded to our bucket as a new table. The only parameters we need to pass are GCP_BIGQUERY_FULL_TABLE_ID (to tell BigQuery where to save this table), and REMOTE_CSV_DESTINATION (to find the CSV we uploaded in our bucket).
Our function will be called gcs_csv_to_table(), and accepts the values above as parameters named full_table_id and remote_csv_path.
"""Create a table from CSV hosted on GCS."""
from google.cloud.bigquery import SourceFormat, LoadJobConfig
from google.api_core.exceptions import BadRequest
from google.cloud.bigquery.table import Table
from .clients import LOGGER, gbq
from config import GCP_BUCKET_NAME
def gcs_csv_to_table(full_table_id: str, remote_csv_path: str) -> Table:
"""
Insert CSV from Google Storage to BigQuery Table.
:param full_table_id: Full ID of a Google BigQuery table.
:type full_table_id: str
:param remote_csv_path: Path to uploaded CSV.
:type remote_csv_path: str
:returns: str
"""
try:
gcs_csv_uri = f"gs://{GCP_BUCKET_NAME}/{remote_csv_path}"
job_config = LoadJobConfig(
autodetect=True,
skip_leading_rows=1,
source_format=SourceFormat.CSV,
)
load_job = gbq.load_table_from_uri(
gcs_csv_uri, full_table_id, job_config=job_config
)
LOGGER.info(f"Starting job {load_job.job_id}.")
LOGGER.success(load_job.result()) # Waits for table load to complete.
return gbq.get_table(full_table_id)
except BadRequest as e:
LOGGER.error(f"Invalid GCP request when creating table `{full_table_id}`: {e}")
except Exception as e:
LOGGER.error(f"Unexpected error when creating table `{full_table_id}`: {e}")insert.py
The first line of our function defines a variable called gcs_csv_uri, which is a simple Google-specific syntax for referring to objects in a bucket:
gs://[GCP_BUCKET_NAME]/[REMOTE_CSV_DESTINATION]URI to files uploaded to a GCS bucket.
BigQuery likes to handle tasks like big data imports or inserts as "jobs", as it should; these methods designed to potentially manipulate massive amounts of data, which may (or may not, in our case) take a very long time. We start by creating a LoadJobConfig, which isn't the job itself, but rather the configuration our insert job will be created from. There's a lot we can pass here, but we go with the following:
- autodetect: When set to
True, the datatype of each column in our CSV will be inferred from its contents. This is generally a very accurate operation, given that you've cleaned your data to make sense. - skip_leading_rows: Skips the first row of our CSV for loading, as this is our row of column headers. BigQuery is able to discern this simply by passing
1. - source_format: BigQuery can accept multiple formats besides CSV files, such as JSON. We need to pass objects provided by BigQuery to specify filetype, hence our import
from google.cloud.bigquery import SourceFormat.
With our job configured, we call load_table_from_uri() from our BigQuery client and save the output to a variable named load_job. Here we pass our two URIs from earlier (the CSV URI and the BigQuery table id), as well as the job config we just created. Calling this method immediately starts the job which defaults as a synchronous operation, meaning our script will not proceed until the job is done. This is fine for our purposes.
We can see this in action by checking the output of load_job.result(), which won't fire until our job has a result (as advertised):
Starting job 15348d51-0f5d-41cf-826c-f0e8c6460ac4.
<google.cloud.bigquery.job.load.LoadJob object at 0x10a5ca910>Output
Let's see what running that job with our fake data looks like in the BigQuery UI:
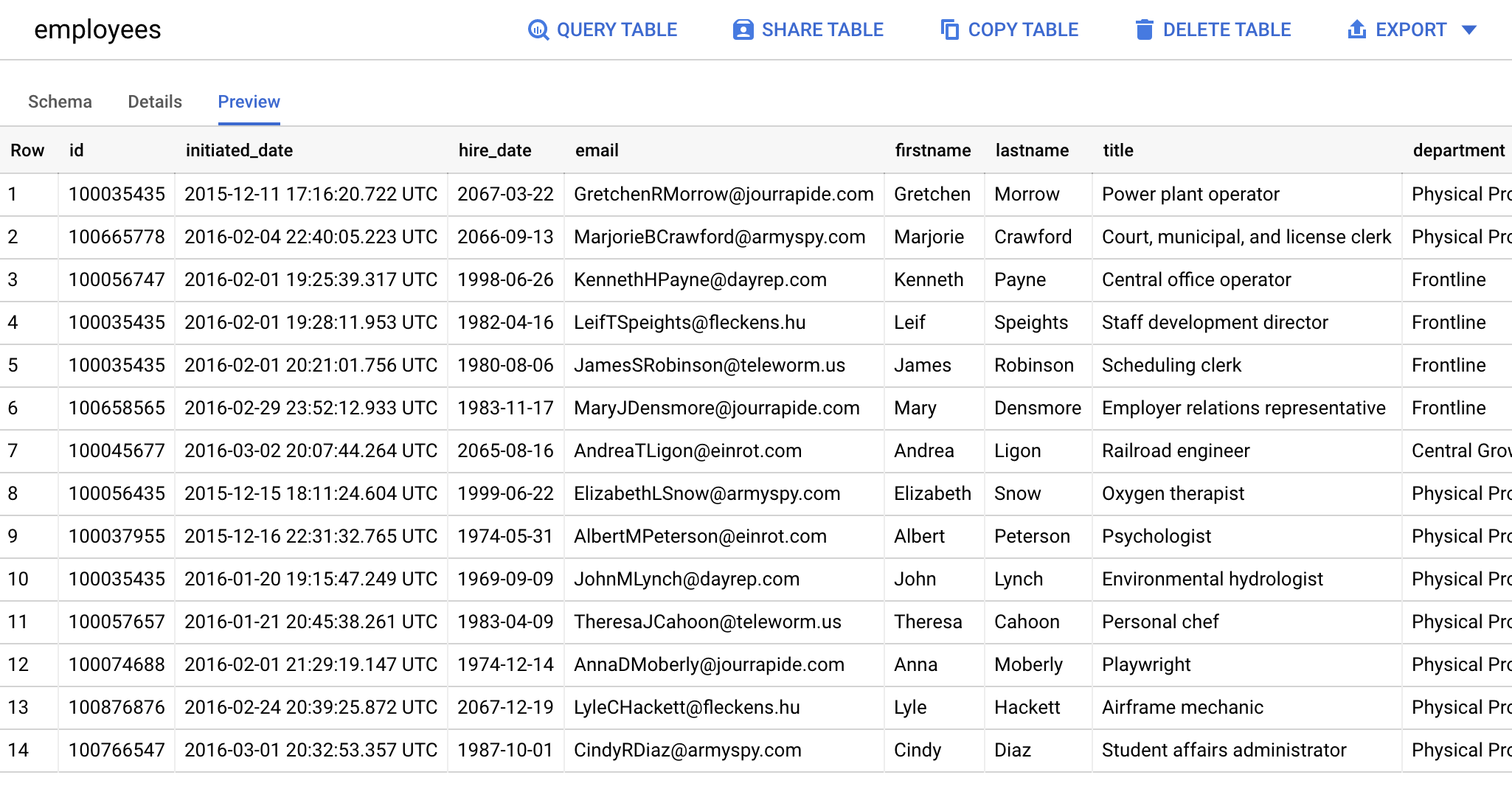
Getting The Inferred Table Schema
Our last function ended by returning the result of a function called get_table(), which we hadn't defined until now:
"""Fetch tables & table schemas."""
from typing import List, Optional, Sequence, Union, Mapping, Any
import pprint
from google.cloud.bigquery.table import Table
from google.cloud.bigquery.schema import SchemaField
from google.api_core.exceptions import BadRequest
from .clients import LOGGER, gbq
def get_table(full_table_id: str) -> Table:
"""
Get a single Google BigQuery table.
:param full_table_id: Full ID of a Google BigQuery table.
:type full_table_id: str
:returns: Table
"""
try:
table = gbq.get_table(full_table_id)
LOGGER.info(f"{table.dataset_id}.{table.table_id}: {table.num_rows} rows.")
return table
except BadRequest as e:
LOGGER.error(f"Invalid GCP request when fetching table `{full_table_id}`: {e}")
except Exception as e:
LOGGER.error(f"Unexpected error when fetching table `{full_table_id}`: {e}")
def get_table_schema(table: Table) -> Sequence[Union[SchemaField, Mapping[str, Any]]]:
"""
Get BigQuery Table Schema.
:param table: Google BigQuery table object.
:type table: Table
:returns: Sequence[Union[SchemaField, Mapping[str, Any]]]
"""
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(table.schema)
return table.schematables.py
get_table() returns a Table object representing the table we just created. Amongst the methods of that class, we can call .schema(), which gives us precisely what we want: a beautiful representation of a Table schema, generated from raw CSV information, where there previously was none.
Behold the fruits of your labor:
[ SchemaField('id', 'INTEGER', 'NULLABLE', None, ()),
SchemaField('initiated_date', 'TIMESTAMP', 'NULLABLE', None, ()),
SchemaField('hire_date', 'DATE', 'NULLABLE', None, ()),
SchemaField('email', 'STRING', 'NULLABLE', None, ()),
SchemaField('first_name', 'STRING', 'NULLABLE', None, ()),
SchemaField('last_name', 'STRING', 'NULLABLE', None, ()),
SchemaField('title', 'STRING', 'NULLABLE', None, ()),
SchemaField('department', 'STRING', 'NULLABLE', None, ()),
SchemaField('location', 'STRING', 'NULLABLE', None, ()),
SchemaField('country', 'STRING', 'NULLABLE', None, ()),
SchemaField('type', 'STRING', 'NULLABLE', None, ())]BigQuery table schema auto-generated from a CSV
There you have it; a correctly inferred schema, from data which wasn't entirely clean in the first place (our dates are in MM/DD/YY format as opposed to MM/DD/YYYY, but Google still gets it right. How? Because Google).
It Doesn't End Here
Auto-generating schemas via Google BigQuery's API is only a small, obscure use case of what Google BigQuery is intended to do. Now if you'll excuse me, I need to stop this fanboying post before anybody realizes I'll promote their products for free forever (I think I may have passed that point).
In case you're interested, the source code for this script has been uploaded to Github below.
hackersandslackers


