

In our last run-in with GraphQL, we used Prisma to assist in setting up a GraphQL server. This effectively gave us an endpoint to work with for making GraphQL requests against the database we specified when getting started. If you're still in the business of setting up a GraphQL server, there are plenty of alternative services to Prisma you could explore. Apollo is perhaps the most popular. A different approach could be to use GraphCMS: a headless CMS for building GraphQL models with a beautiful interface.
With our first models are created and deployed, we’re now able to explore GraphQL hands-on. Prisma (and just about any other service) gives us the luxury of a “playground” interface, where we can write all sorts of nonsensical and otherwise dangerous shit. This is our opportunity to get comfortable before unleashing our ignorance upon the world in a production environment. To guide us, I’ll be using my own example of creating models, importing dummy data, and how to write the queries to fetch said data.
Our Example Model
In my case, I created a model for one of my favorite things: JIRA issues. I'll be creating a Kanban widget using the data we play with here down the line, so this is a real live use-case we'll be working with.
Here are the contents of my datamodel.prisma file:
type jiraissue {
id: ID! @unique,
key: String! @unique,
assignee: String,
summary: String,
status: String!,
priority: String,
issuetype: String,
epic_name: String,
updated: DateTime,
rank: Int,
timestamp: Int,
project: String
}You'll notice we have a good number of datatypes here, as well as two unique keys. In case this point has been missed before, the exclamation marks in our model denote a required field.
Deploying this model results in the following PostgreSQL query:
CREATE TABLE "default$default"."jiraissues" (
"id" varchar(25) NOT NULL,
"key" text NOT NULL,
"assignee" text,
"summary" text,
"status" text NOT NULL,
"priority" text,
"issuetype" text,
"epic_name" text,
"updated" timestamp(3),
"rank" int4,
"timestamp" int4,
"project" text,
"updatedAt" timestamp(3) NOT NULL,
"createdAt" timestamp(3) NOT NULL,
PRIMARY KEY ("id")
);Looks like everything lines up! The only caveats are the updatedAt and createdAt fields: Prisma adds these to every database table for us.
Here's a sample of the data I added by connecting to my database and importing a CSV:
| id | key | assignee | summary | status | priority | issuetype | epic_name | updated | rank | timestamp | project | updatedAt | createdAt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 430 | HACK-769 | Todd Birchard | Fix projects dropdown | Done | Medium | Bug | Projects Page | 2019-02-15 00:00:00 | 3 | 1550224412 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
| 465 | HACK-782 | Todd Birchard | Lynx: on mobile, instead of full link, show domainname.com/... | To Do | Low | Task | Widgets | 2019-02-15 00:00:00 | 4 | 1550223282 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
| 472 | HACK-774 | Todd Birchard | New Widget: Next/Previous article in series | To Do | High | Task | Widgets | 2019-02-14 00:00:00 | 2 | 1550194799 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
| 464 | HACK-778 | Todd Birchard | HLJS: set indentation level | Backlog | Medium | Task | Code snippets | 2019-02-14 00:00:00 | 3 | 1550194791 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
| 481 | HACK-555 | Todd Birchard | Minify Babel | Backlog | Medium | Task | Optimization | 2019-02-14 00:00:00 | 3 | 1550194782 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
| 432 | HACK-777 | Todd Birchard | Redesign footer to be informative; link-heavy | Done | Medium | Task | Creative | 2019-02-14 00:00:00 | 2 | 1550102400 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
| 433 | HACK-779 | Todd Birchard | Changeover from cloudinary to DO | Done | Highest | Task | Urgent | 2019-02-14 00:00:00 | 0 | 1550102400 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
| 428 | HACK-775 | Todd Birchard | Update issuetype icons | To Do | Low | Data & Analytics | Projects Page | 2019-02-14 00:00:00 | 3 | 1550102400 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
| 374 | HACK-710 | Todd Birchard | Implement auto text synopsis for Lynx posts | Done | High | Task | Lynx | 2019-02-14 00:00:00 | 1 | 1550102400 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
| 185 | HACK-395 | Todd Birchard | Create fallback image for posts with no image | To Do | Low | Task | Page Templates | 2019-02-14 00:00:00 | 3 | 1550102400 | Hackers and Slackers | 2019-03-02 15:43:59.419 | 2019-03-02 15:43:59.419 |
A Few Things About GraphQL Queries
Before going any further, let's touch on a few concepts that are easy to stumble over.
Firstly, a GraphQL API only has a single endpoint. It makes sense: the logic of GraphQL API hits sit with the person creating the queries. That said, we've all been building REST APIs long enough to have this slip past us; I caught myself thinking through how to separate which endpoints I wanted before remembering that's entirely not how this works.
It's import to understand that GraphQL is designed to be explicit. A significant advantage of GraphQL is that we can be sure only to return the information which is essential to us. For applications looking to optimize system resources (such as mobile apps), avoiding massive payloads is a feature, not a bug. This explains many of the design decisions which went into designing GraphQL, as you'll see it's intentionally difficult (but possible) to create a "get all records" query.
Lastly, GraphQL allows us to create queries in both shorthand and long-form formats. We'll take a look at both, starting with shorthand.
GraphQL Shorthand Queries
Shorthand queries are an excellent place to start for beginners like us just trying to get some data out of our database.
The structure of such a query looks like this:
{
[model_name]s {
[desired_field_name_1]
[desired_field_name_2]
[desired_field_name_3]
}
}Our model_name in this case would be jiraissue made plural, resulting in jiraissues. This is an important thing to note: when creating models, we should name them as a single entity, as things get confusing very fast otherwise. I initially made the mistake of naming my model jiraissues, which would then drive me to query jiraissueses. That was a fun little trip (I believe this is unique to Prisma).
Within the brackets of our model, we must explicitly specify which fields (aka database columns) we'd like returned with our query. Here's a full example of a shorthand query:
{
jiraissues {
key
summary
epic_name
}
}Check out what this results in when entered in our "playground":
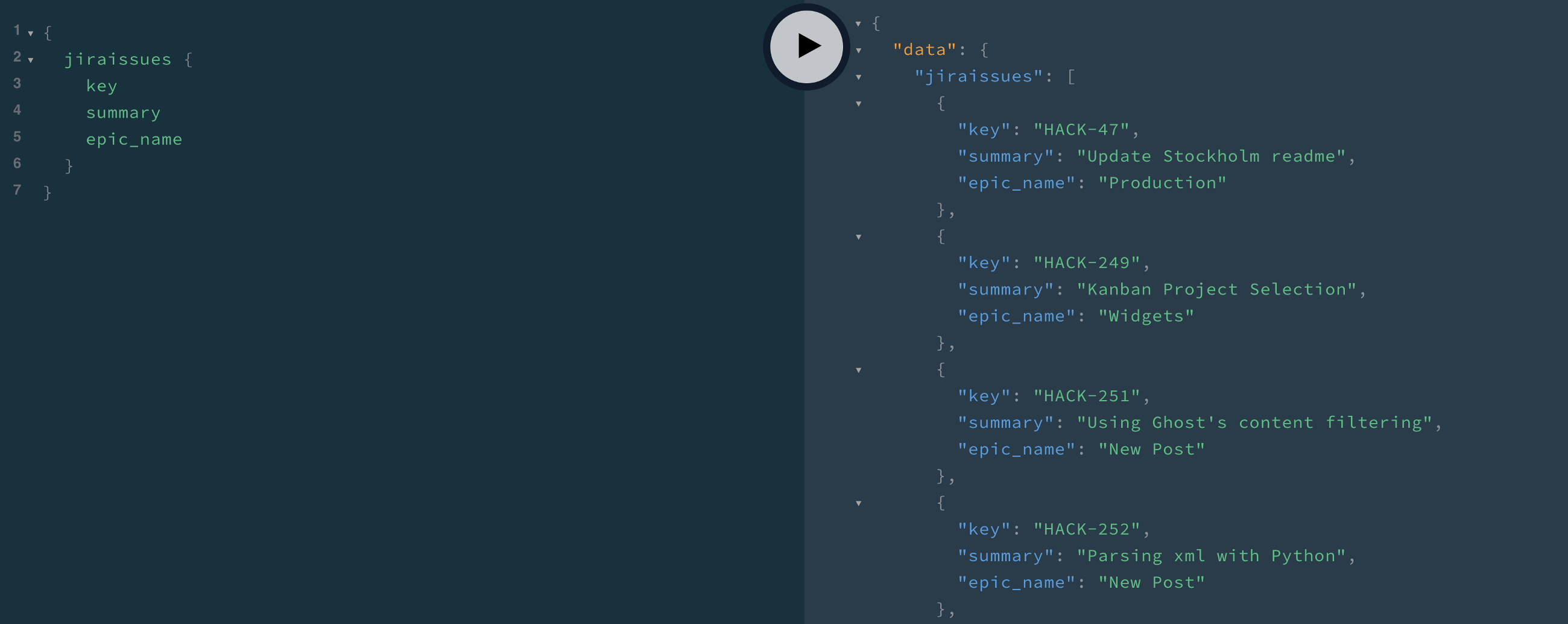
Just like that, we have liftoff!
The "Where" Clause
As mentioned earlier, a major point of GraphQL is to return only the data which is necessary. Thus, we should almost always make queries with a where clause. Thus, we can extend our simple query as such:
{
jiraissueses(where: {status: "Backlog"}) {
key
summary
epic_name
status
}
}And here's the result:
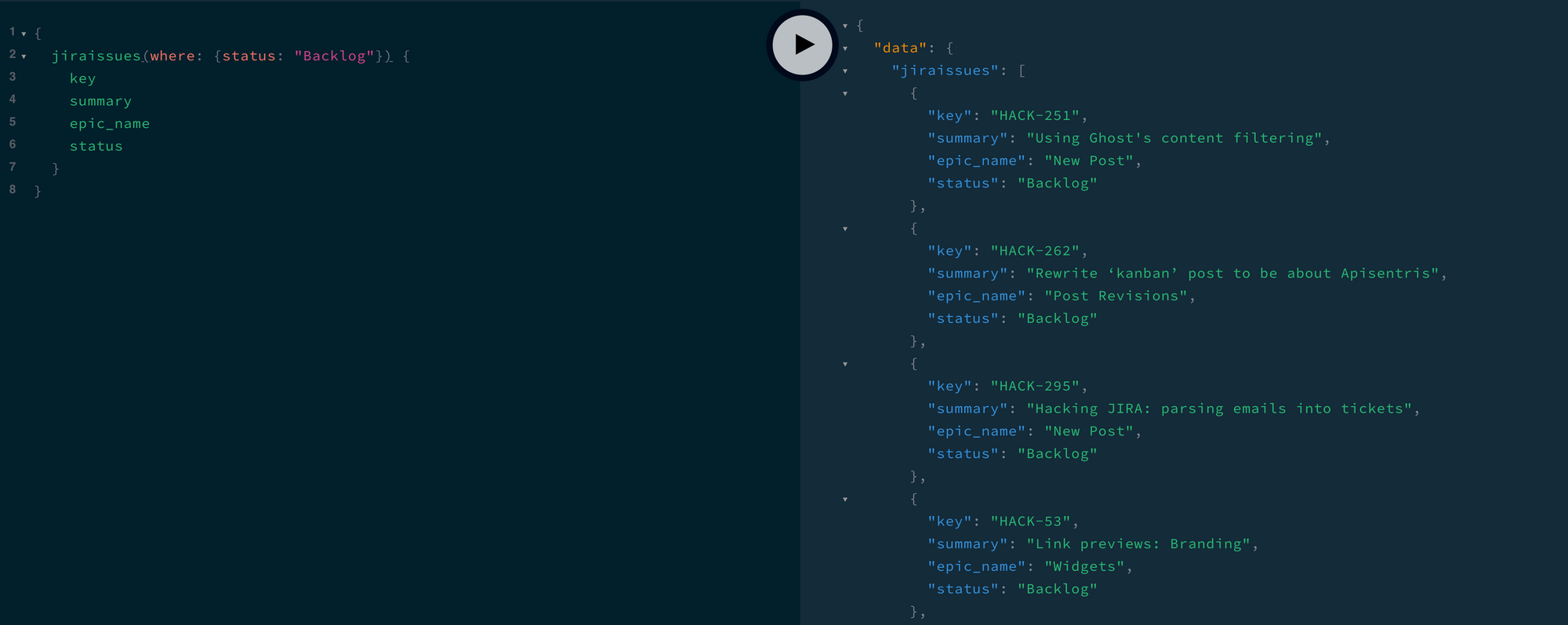
Adding to Our Query
Just like SQL or MongoDB queries, we can add more to our query to get more specific:
{
jiraissues(
where: {status: "Backlog", project: "Hackers and Slackers"},
orderBy: updated_DESC,
first: 6
) {
key
summary
epic_name
status
updated
}
}Here, we've expanded our filter to work on two fields: now our query will only return issues which match our criteria for both status and project.
We've also added a few other things to our query. With orderBy, we can set the order in which records will be returned to us by field, either in ascending (ASC) or descending (DESC) order. first imposes a limit on our results, giving us the first 6 which meet our criteria. Alternatively, last would give us the opposite.
There are plenty of more parameters we could add here. For example:
[fieldname]_contains: Filters results where the string field contains a substring.[fieldname]_in: Checks a list to return records where the value of the field matches any substring in a provided list.[fieldname]_starts_with: An expression to check for values that start with a provided substring.[fieldname]_ends_with: Similar to the above, only for ending with a substring.
Not only are there more to add to this list, but each as an accompanying reverse statement which would return the opposite. For example, [fieldname]_not_contains is the opposite of [fieldname]_contains.
GraphQL Long-form Queries
What we've seen so far is already pretty powerful, but we're far from seeing just how far GraphQL can go.
To demonstrate what a more complicated query is capable of, let's use our Kanban board example. Our board is going to have 4 columns representing 4 statuses: Backlog, To Do, In Progress, and Done. Check out how we can receive all of this with a single query:
query KanbanJiraIssues {
backlog: jiraissues(where: {status: "Backlog", project: "Hackers and Slackers"}, orderBy: updated_DESC, first: 6) {
key
status
summary
assignee
priority
issuetype
epic_name
updated
rank
timestamp
project
}
todo: jiraissues(where: {status: "To Do", project: "Hackers and Slackers"}, orderBy: updated_DESC, first: 6) {
key
status
summary
assignee
priority
issuetype
epic_name
updated
rank
timestamp
project
}
inprogress: jiraissues(where: {status: "In Progress", project: "Hackers and Slackers"}, orderBy: updated_DESC, first: 6) {
key
status
summary
assignee
priority
issuetype
epic_name
updated
rank
timestamp
project
}
done: jiraissues(where: {status: "Done", project: "Hackers and Slackers"}, orderBy: updated_DESC, first: 6) {
key
status
summary
assignee
priority
issuetype
epic_name
updated
rank
timestamp
project
}
}
Unlike our shorthand queries, we begin this query with the syntax query [your_query_name]. You can name your query anything you'd like.
Within that query, we can perform multiple individual queries which we also give display names. In whole, the structure looks like this:
query [your_query_name] {
[subquery_name]: [model_name]s(where: {[your_criteria]}){
[desired_field_name_1]
[desired_field_name_2]
[desired_field_name_3]
}
}Check out the result:
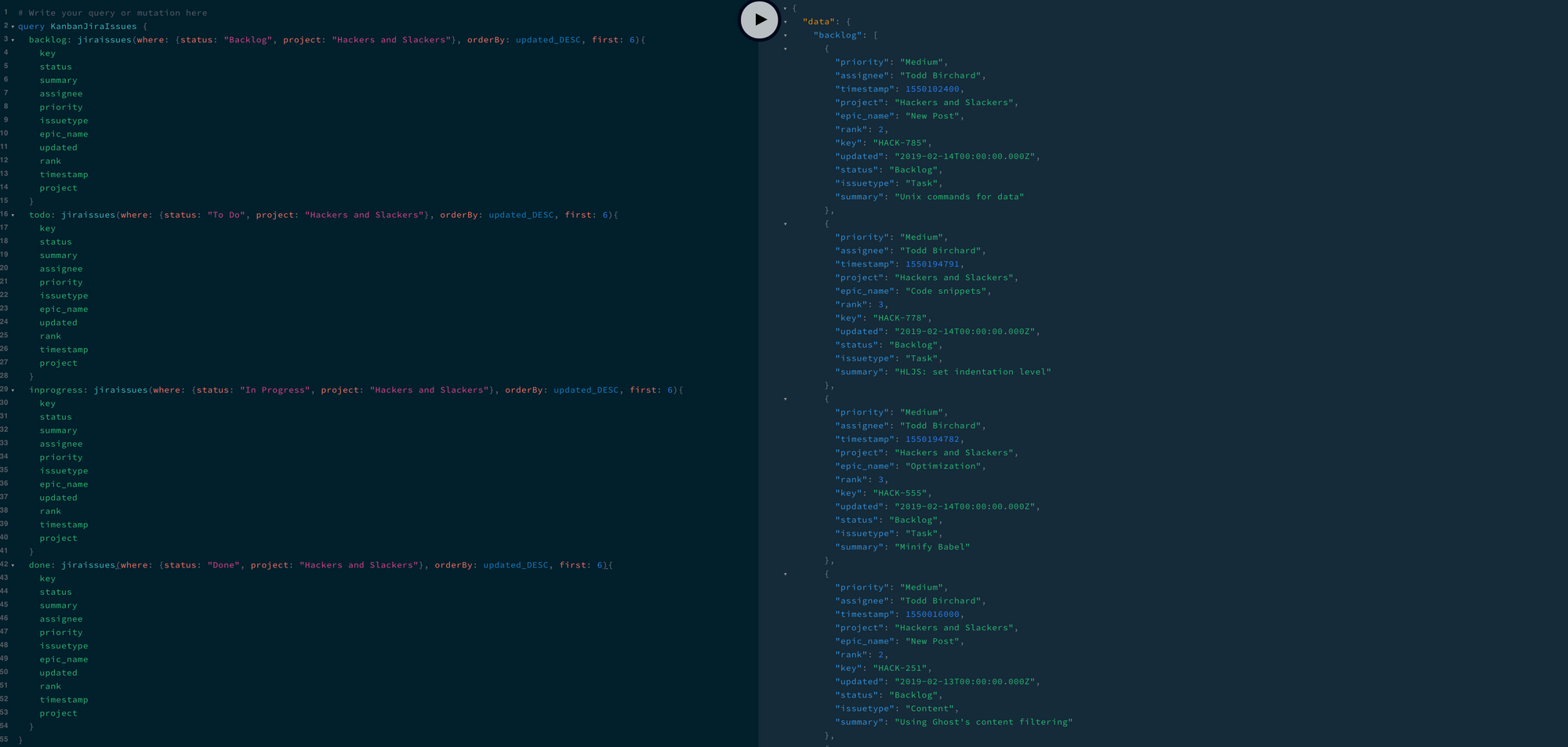
This format has helped us accomplish something previously impossible with REST APIs: we've used a single endpoint to give us exactly the information we need while omitting the information we don't.
Passing Variables Into Queries
As you can see, queries can get long pretty quick. It would suck if we had to write the entirety of the query above every time we wanted to hit an API. Luckily, we don't don't have to: that's where GraphQL variables come in.
Variables allow us to use the structure of a GraphQL query repeatedly, while providing different values where we see fit. That means if we have a particularly complicated query structure that we'd like to repurpose, we can pass dynamic values into said query. This is where things start to get really powerful.
Let's assume that finding JIRA issues by epic link is a common task we'll have to deal with. This is how we'd pass a dynamic value for epic_link:
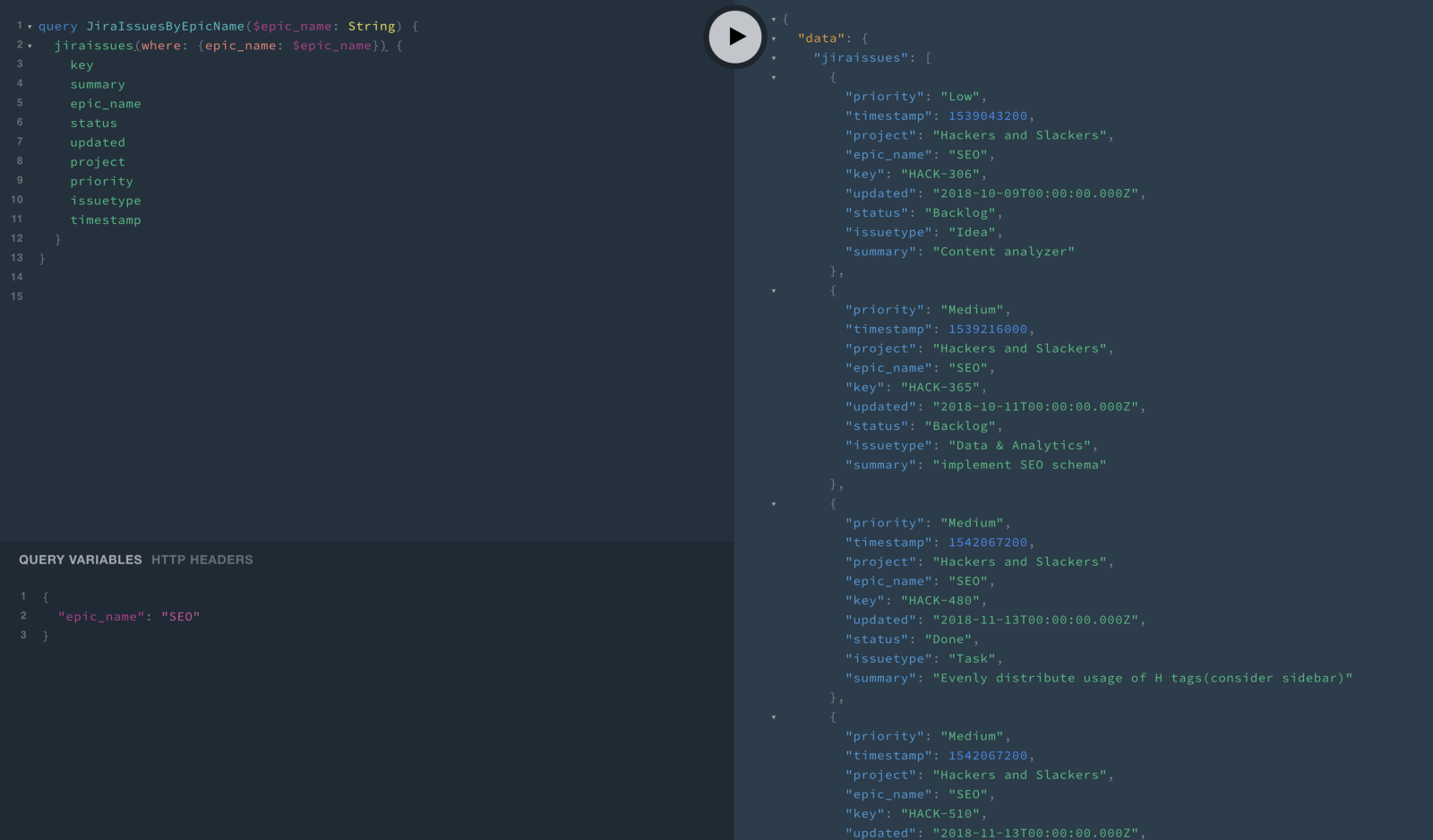
query JiraIssuesByEpicName($epic_name: String) {
jiraissues(where: {epic_name: $epic_name}) {
key
summary
epic_name
status
updated
project
priority
issuetype
timestamp
}
}$epic_name is the name of our variable, which we set in the object we pass to the query. That object looks like this:
{
"epic_name": "SEO"
}So what we're saying on line 1 is that we're passing a variable named $epic_name, and that variable will be a String. When $epic_name appears again on line 2, the variable is interpreted as its value, which is "SEO".
Luckily, our playground has a place specifically for setting variables which get passed to our queries. Here's how it all looks:
Unlimited Power?
While GraphQL's syntax looks clean and simple at first glance, it's easy to see how quickly simple queries evolve into complex behemoths. It's no coincidence that all GraphQL services come with a playground. It's hard to imagine how anybody could internalize GraphQL syntax without trial and error, and we're only getting started.
So far we've only queried existing data; we haven't even begun to touch on mutations yet. Catch us next time when we start modifying data and get ourselves into a whole lot of trouble.



