

Last week we encountered a genuine scenario when working with GraphQL clients. When building real applications consuming data via GraphQL, we usually don't know precisely the query we're going to want to run at run time. Imagine a user cruising through your application, setting preferences, and arriving at core pieces of functionality under a content which is specific only to them. Say we're building a GrubHub knockoff (we hate profits and love entering impenetrable parts of the market, it's not that uncommon really.) At its core, the information we're serving will always be restaurants; we'll always want to return things like the restaurant address, name, rating, etc. Because we want our app to be intelligent, this means that circumstances in which User 1 makes a query are vastly different than User 2. Aside from the obvious facts (residing in different locales), perhaps there's more metadata we can leverage from User 1's long-term app usage, versus User 2 who is a total noob to our knockoff app.
Yet, the information we're serving will always be restaurants. There's a core query being reused at the heart of our requests: we need to be dynamic enough to account for the fact that User 1 has checked off 13 different cuisines and strict delivery time windows, whereas User 2 doesn't give a shit. User 2 just wants pizza.
This is where GraphQL Fragments come in to play. We've already seen how we can pass variables through our queries to receive contextual data: the next step is creating blocks of reusable code which may never change, which become the foundational building blocks of all future queries.
When to Use Fragments
Back to our JIRA example, I demonstrated precisely the sort of thing one should never do: making more than one GraphQL request to serve a single purpose.
To recap, we're pulling in JIRA issues to a Kanban board. Our board has 4 columns: one per "status." Here's a god-awful way of hardcoding a query like that:
query JiraIssuesByStatus($project: String, $status: String) {
backlog: jiraIssues(where: {project: $project, status: $status}, orderBy: updated_DESC, first: 6) {
key
summary
epic_color
epic_name
status
priority_rank
priority_url
issuetype_name
issuetype_url
assignee_name
assignee_url
}
todo: jiraIssues(where: {project: $project, status: $status}, orderBy: updated_DESC, first: 6) {
key
summary
epic_color
epic_name
status
priority_rank
priority_url
issuetype_name
issuetype_url
assignee_name
assignee_url
}
progress: jiraIssues(where: {project: $project, status: $status}, orderBy: updated_DESC, first: 6) {
key
summary
epic_color
epic_name
status
priority_rank
priority_url
issuetype_name
issuetype_url
assignee_name
assignee_url
}
done: jiraIssues(where: {project: $project, status: $status}, orderBy: updated_DESC, first: 6) {
key
summary
epic_color
epic_name
status
priority_rank
priority_url
issuetype_name
issuetype_url
assignee_name
assignee_url
}
}Seems like a lot of repetition, yeah? What if we could define chunks of queries to be reused to simplify things?
# Write your query or mutation here
fragment JiraFields on jiraIssue {
key
summary
epic_color
epic_name
status
priority_rank
priority_url
issuetype_name
issuetype_url
assignee_name
assignee_url
}
query JiraIssuesViaFragments($project: String) {
backlog: jiraIssues(where: {status: "Backlog", project: $project}, orderBy: updated_DESC, first: 6) {
...JiraFields
}
todo: jiraIssues(where: {status: "To Do", project: $project}, orderBy: updated_DESC, first: 6) {
...JiraFields
}
progress: jiraIssues(where: {status: "In Progress", project: $project}, orderBy: updated_DESC, first: 6) {
...JiraFields
}
done: jiraIssues(where: {status: "Done", project: $project}, orderBy: updated_DESC, first: 6) {
...JiraFields
}
}Progress! Instead of reiterating the fields we want to query for each time, we set these once. We do this by creating a fragment named JiraFields (naming conventions for fragments are totally up to you- these don't relate to anything). To make this easier to visualize, let's just look at the parts:
fragment [GivenNameToYourFragment] on [DatamodelToQuery(SINGULAR)] {
[fields]
}Take note of [nameOfDatamodelToQuery(SINGULAR)]. Our fragment will refer to data model in the singular syntax - this is important.
Our New Query Using a Fragment
Again, let's simply what we're looking at:
query [GivenNameToYourQuery]($project: String) {
[subsetName]: [DatamodelToQuery(PLURAL)](where: {status: "Backlog", project: $project}) {
...[GivenNameToYourFragment]
}
}[subsetName]is the name of the embedded JSON object to be returned in the response. The naming is up to us.[DatamodelToQuery(PLURAL)]contrasts the singular data model we specified in our fragment.- Finally,
...[GivenNameToYourFragment]is the syntax for dumping a fragment into a query. Yes, the...is intentional.
Here's how we managed to get on:
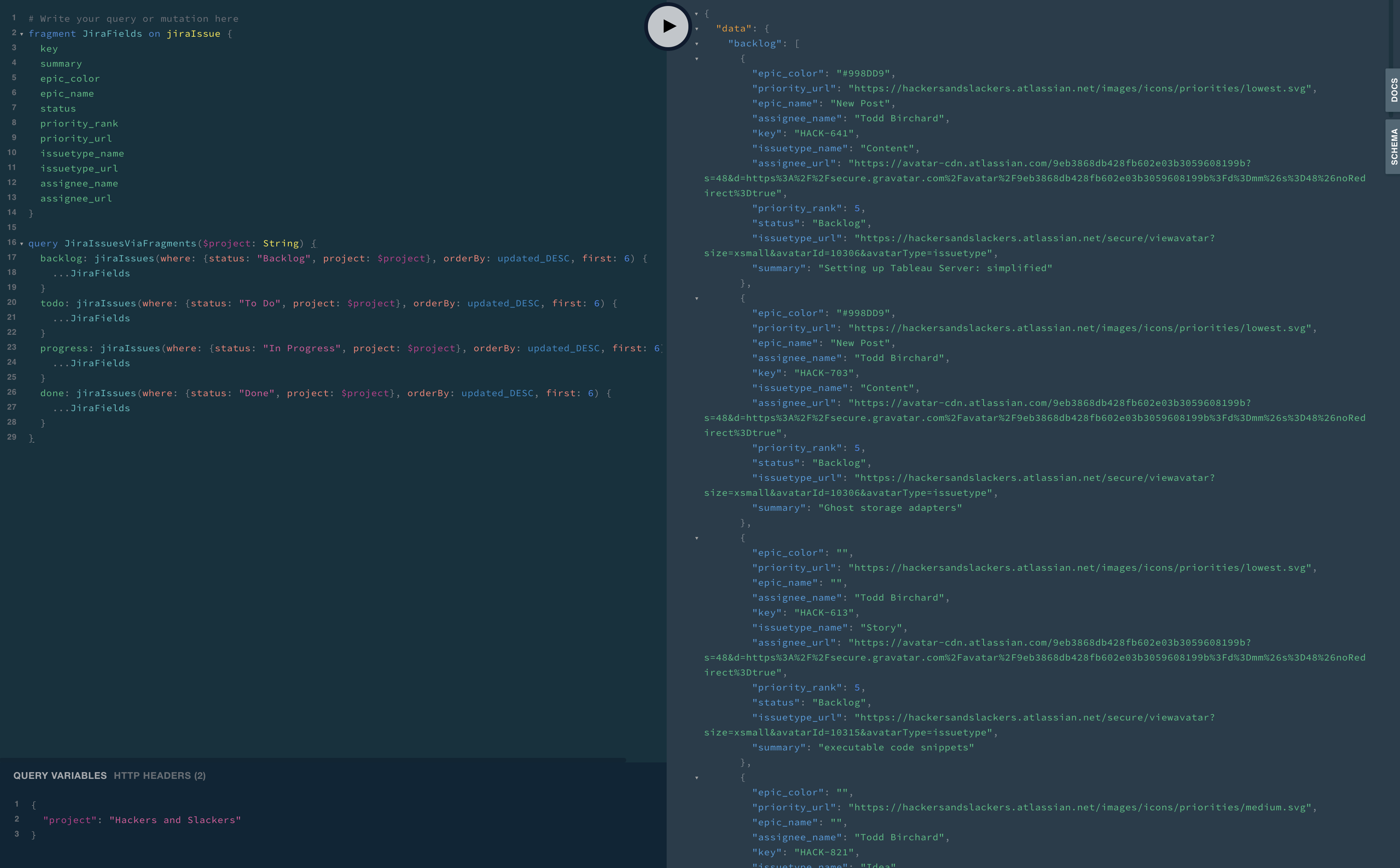
Implementing On The Client Side
With the big picture in hand, this is still all theoretical until we have some real code making real dynamic queries. So which GraphQL client tools should we use?!?! Sweet baby Jesus have mercy, I wish I had a straight answer.
As we all know, Apollo is crushing the game with their seemingly endless libraries doing... a lot of similar stuff? Then there's Prisma, the new hotshot looking to make a buck. But what about this repo? It seems totally fine, but why won't it freakin work?! And what about this Lokka thing? Also, apparently you can just use node-fetch anyway?
For somebody looking for simplicity, this gets very frustrating. Most clients are immediately concerned with integrating with React as fast as possible (totally understandable), but a small-town country boy like me just wants to start with simple. I'm just trying to write a god damn tutorial!
Anyway. The GraphQL ecosystem is was it is: we'd be foolish to think anything related to JavaScript could be cohesive or straightforward. Instead of wrestling with that reality, now's as good a time as ever to move on to the part of GraphQL we've failed to speak of: modifying data.
GraphQL Mutation Cheatsheet
Any form of creating, changing, or deleting data in GraphQL falls under the umbrella of mutations. The structure is similar to queries, except that we take data in (presumably through variables) and spit out whichever fields you'd like to see as a result of that.
Creating Records
A functioning "create" mutation with the resulting response:

And the mutation itself, just in case anybody is copy/pasting out there:
mutation CreateJiraIssue($key: String!, $summary: String!, $status: String!) {
createjiraissues(data: {key: $key, status: $status, summary: $summary}) {
key
status
summary
}
}Updating Records
We can update records (aka nodes) by specifying the target node using where: {}, and the data to be updated within data: {}
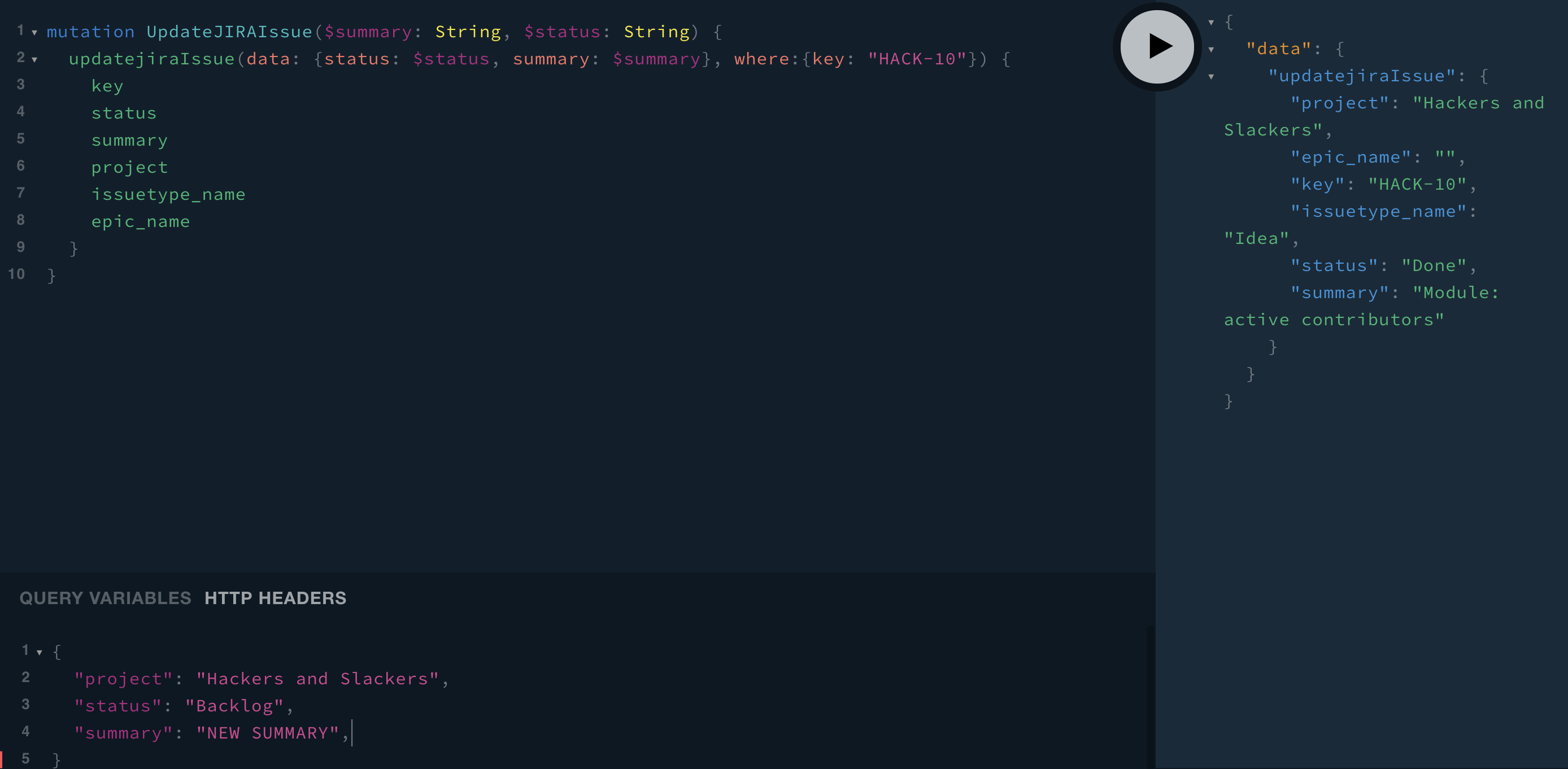
mutation UpdateJIRAIssue($summary: String, $status: String) {
updatejiraIssue(data: {status: $status, summary: $summary}, where:{key: "HACK-10"}) {
key
status
summary
project
issuetype_name
epic_name
}
}Deleting Records
You can even specify which fields you want returned from the node you're in the act of ruthlessly murdering!
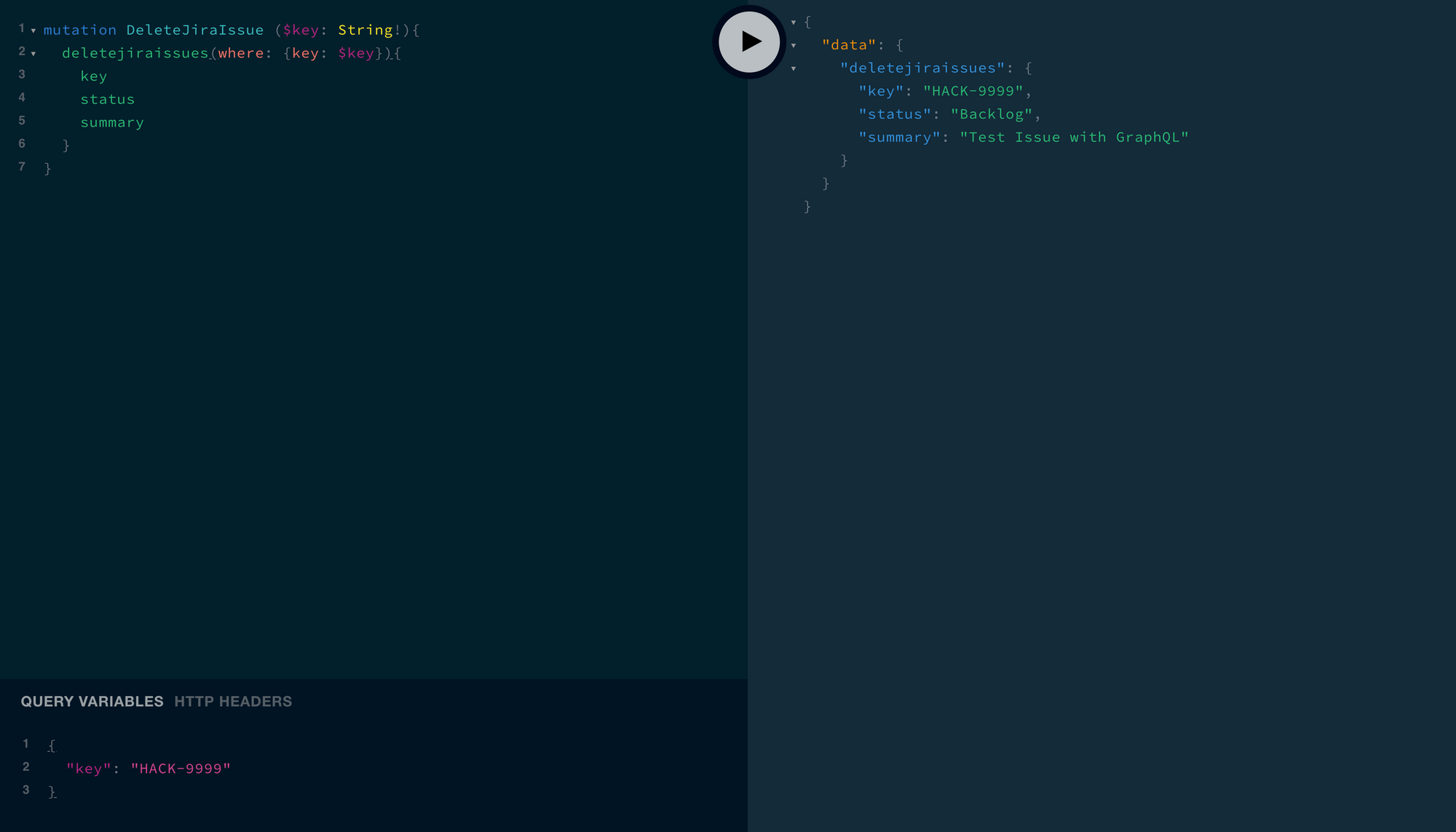
mutation DeleteJiraIssue ($key: String!){
deletejiraissues(where: {key: $key}){
key
status
summary
}
}Enough For Now
Hopefully, I'm not the only one to have bee deceived by the simplicity of GraphQL's syntax at first glance. The minimalism of GraphQL queries and mutations would lead one to believe that they're simple to understand right off the bat. The problem with that logic is the syntax is so simplistic, that there's hardly any way of telling what nearly identical queries or mutations might do from one character to the next. Even in JSON, the combination of explicit quotations, key:value relationships, and comma-separation affords us a lot of inferred knowledge we take for granted.
I'm not saying GraphQL is wrong, or painstakingly difficult to pick up, as much as it can easily be frustrating to newcomers (and rightfully so). As long as people keep reading, I'll keep posting, so let's chip away at this thing week by week.



