

It's fair to say that most Hackers and Slackers readers share one thing: we like writing stuff in Python. This does not make us unique; it reflects a well-known, and easily explainable phenomenon as Data Scientists/Engineers enter (and more recently, leave) a space previously reserved for software engineering: multi-purpose programming languages. Despite how unique these disciplines are from one another, we share a common trait. To quote the Beatles, All we Need is Python™️.
And yet, each journey has a defining moment where it's clear the language has surpassed its 30th birthday. It's been three decades since Guido unleashed The Serpent to tackle the problems of 1991. This was the final year of the Cold War era: a different time in history and even more so in computing. Most of the design decisions behind Python were sensible for their time, but a few of these decisions have become today's "quirks." The most controversial quirk is easily the topic of concurrency.
Indeed, I'm referring to the Global Interpreter Lock (GIL). I'll save you the pain of disparaging the GIL as others have done a much better job of doing this than I can (if you're interested in the nitty-gritty and have the time, I highly recommend a piece entitled The GIL and its effects on Python multithreading). The long and short of the GIL is that it restricts Python from utilizing multiple CPU cores effectively, leaving your 8-core laptop running Python scripts on a single core while others lay idle.
Concurrency is a complicated problem extending far beyond Python; most programming languages share a similar fate. But we're not here to lament our circumstances; we're here to talk about asynchronous I/O.
Doing Multiple Things at Once in Python
Concurrency is a broad concept in programming that boils down to "doing a bunch of stuff at once." Code that is said to run concurrently generally takes one of two possible forms:
- Tasks take turns to be executed to minimize downtime of peers' tasks.
- Tasks that truly tun run parallel to one another, simultaneously.
Python ships with two modules that handle either approach, Respectively:
- Threading (single process): Python's threading module is limited to utilizing a single processor at a given time. The threading module enables the governance of tasks occupying a given thread. Task X runs until blocked by an external factor (such as awaiting a response to an HTTP request). In the meantime, Task Y is prioritized to execute it until Task X is ready to continue (hence "blocking I/O").
- Multiprocessing (multiple processors): The multiprocessing module enables code to run in parallel. A script is initialized and run n times simultaneously across n CPUs. Expanding a single road into an 8-lane highway has obvious performance benefits until it comes time to consolidate the results of each task. Multiple processes cannot simultaneously write data to the same destination (databases, files, etc.) without creating locks that block one another. For scripts intended to produce an output, attempting to wrestle this problem is almost certainly an insurmountable endeavor.
Where Does Asyncio Fit In?
Asyncio is a third and generally preferred alternative to the approaches above. Despite being limited to a single thread, Asyncio can execute a high volume of operations much faster than Python's native single-threaded execution. To illustrate how this is possible, consider how human beings tend to "multitask." When people claim to be "multitasking," they generally get things done by juggling between tasks instead of doing multiple things simultaneously. Single-threaded programs are asynchronous in the same way: output is optimized by overlapping work.
While humans are notoriously awful at multitasking, machines can see significant performance benefits from this practice. They are generally better suited to start and stop work without the extraneous overhead. This concept is the "secret sauce" of frameworks such as FastAPI, an asynchronous Python framework that self-proclaims performance to be "on par with NodeJS and Go" (I promise to write a fair share on FastAPI another time).
It took me a while to break my skepticism of how a single thread handling multiple tasks kind of at the same time could deliver a performance benefit worth writing about. It wasn't until I stumbled upon the concept of event loops that things started making sense.
Event Loops
We start with a backlog of I/O "tasks." They can be HTTP requests, saving things to disk, or in our case, a mix of both. Synchronous Python workflows (read: standard Python) would execute each task one at a time, from start to finish. It's like waiting in line at the DMV, where there's only one line, and the lady hates all of you.
An event loop handles things differently to get through tasks quicker. Given many tasks, an event "loop" works by grabbing new tasks and delegating them to threads. The loop continuously checks the tasks in progress for downtime (or completion). When delegated tasks are "waiting" on an external factor (such as an HTTP request), the event loop fills the dead time by kicking off another task in the thread. If the event loop finds that an allocated task has been completed, the Task is removed from its thread, the output of that Task is collected, and the loop picks another task from the queue to occupy the thread:
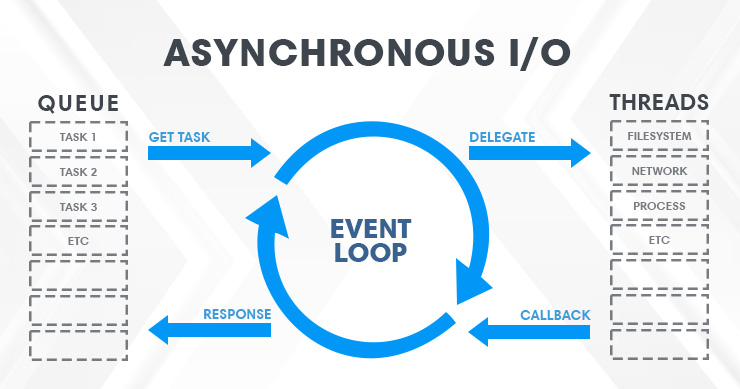
Unlike a DMV line, an event loop works somewhat similarly to a restaurant (stick with me here). Despite having many tables and a single kitchen, a server handles their "backlog" by rotating between tables (tasks) and a kitchen (thread). It's much more efficient to take multiple food orders in succession to be prepared in a kitchen than taking single orders and waiting for them to be created/served before moving to the next customer.
Coroutines: Functions to Run Asynchronously
Asynchronous Python scripts don't define functions - they define coroutines. Coroutines (defined with async def, as opposed to def) can halt execution before completion, typically waiting on the completion of another coroutine. The snippet below demonstrates the simplest example of a coroutine:
"""Define a Coroutine function to be executed asynchronously."""
import asyncio
from logger import LOGGER
async def simple_coroutine(number: int):
"""
Wait for a time delay & display number associated with coroutine.
:param int number: Number to identify the current coroutine.
"""
await asyncio.sleep(1)
LOGGER.info(f"Coroutine {number} has finished executing.")coroutines.py
simple_coroutine() halts its execution for 1 second before logging a message. Coroutines can't be invoked like regular functions; attempting to run simple_coroutine(1) won't work unless it's run inside an asyncio event loop. Luckily, creating an event loop is easy:
import asyncio
from coroutines import simple_coroutine # Import our coroutine
asyncio.run(simple_coroutine(1))Running a Coroutine
asyncio.run() creates an event loop, and runs the coroutine passed into it. Creating an event loop is best when your script has an entry point from which all logic originates. Alternatively, asyncio.gather() accepts any number of coroutines, if you'd prefer to simply execute a handful of coroutines:
import asyncio
from coroutines import simple_coroutine # Import our coroutine
asyncio.gather(
simple_coroutine(1)
simple_coroutine(2)
simple_coroutine(3)
)Running 3 coroutines inside an event loop
Running this script will execute all three coroutines and log the following:
1
2
3Output of asyncio.gather() with three coroutines
How long would you suppose the above operation takes to complete? 3 seconds, perhaps? Or have we managed to optimize our code with sorcery?
You might be surprised to learn that running the above consistently executes in almost one second (or occasionally 1.01 on a bad day). If we time our function's execution time using Python's built-in time.perf_counter(), we can see this first-hand:
import asyncio
import time
from coroutines import simple_coroutine # Import our coroutine
def async_gather_example()
start_time = time.perf_counter()
asyncio.gather(
simple_coroutine(1)
simple_coroutine(2)
simple_coroutine(3)
)
print(
f"Executed {__name__} in {time.perf_counter() - start_time:0.2f} seconds."
)
async_example()Track execution time of executing 3 coroutines which sleep for 1 second
Sure enough, the script takes almost exactly 1 second:
Executed async_example in 1.01 seconds.
Output of async_example()
Our coroutine simple_coroutine() takes 1 second to execute on its own. What's impressive about the above is we've called this coroutine three times and got a runtime of nearly 1 second, whereas a synchronous Python script indeed would've taken 3 seconds. What's more, the overhead for executing these tasks was only less than .01 seconds, meaning the coroutines we completed at almost the same time.
Working with Tasks
Using asyncio.gather() in the above example, we side-stepped an essential data structure in Asyncio: the Task.
Coroutines are functions that can run asynchronously. It would be nice to "manage" these functions when running hundreds or thousands of such functions in specific ways. Knowing when a coroutine fails (and what to do with it), or simply checking in on which coroutine a loop is currently handling, especially when our event loop might take minutes or hours to execute or have the potential to fail.
Managing Tasks
In more complex workflows, Tasks offer several useful methods to help us manage Tasks being executed:
.set_name([name])(and.get_name()): Gives the task a name to have a human-readable way to identify which task is which..cancel(msg=[message]): Cancels a task in an event loop, allowing the loop to continue with other tasks. Useful for tasks that become unresponsive or are unlikely to complete..canceled(): ReturnsTrueif the task was canceled, orFalseotherwise..done(): ReturnsTrueif the task was completed successfully, orFalseotherwise..result(): Returns the result of the task.canceledtasks will include the exception message for why the task was canceled, whereasdonetasks will simply returndone. A task that has yet to be invoked will return anInvalidStateErrorexception.- A bunch of other methods, are all found in Asyncio's Task documentation.
Creating Tasks
Wrapping Coroutines with Asyncio Task is simple. Running asyncio.gather() earlier handled this for us, but this is simply a shortcut that deprives us of utilizing the upsides of Tasks, as the tasks are instantiated as generic objects and executed immediately. If we create our tasks beforehand, we can associate metadata with them and execute them in an event loop when we're ready.
We're going to create a new coroutine called create_tasks(), which is a coroutine that will:
- Creates n Task instances of
simple_coroutine(). - Assigns each Task a name upon creation.
- Returns all Tasks as a Python list, which can later be executed via an event loop:
"""Create multiple tasks from a Coroutine."""
import asyncio
from asyncio import Task
from typing import List
from logger import LOGGER
from asyncio_intro_part1.coroutines import simple_coroutine
async def create_tasks(num_tasks: int) -> List[Task]:
"""
Create n number of asyncio tasks to be executed.
:param int num_tasks: Number of tasks to create.
:returns: List[Task]
"""
task_list = []
LOGGER.info(f"Creating {num_tasks} tasks to be executed...")
for i in range(num_tasks):
task = asyncio.create_task(
simple_coroutine(i),
name=f"Task #{i}"
)
task_list.append(task)
LOGGER.info(f"Created Task: {task}")
return task_listtasks.py
Tasks in Action
With our create_tasks() method defined, it's time for the fun part: seeing tasks being created, executed, and completed. At the root of our project, we'll define one last function, async_tasks_example()to demonstrate this:
...
from .tasks import create_tasks
async def async_tasks_example():
"""Create and inspect tasks to wrap simple functions."""
task_list = await create_tasks(5)
done, pending = await asyncio.wait(task_list)
if done:
LOGGER.success(
f"{len(done)} tasks completed: {[task.get_name() for task in done]}."
)
if pending:
LOGGER.warning(
f"{len(done)} tasks pending: {[task.get_name() for task in pending]}."
)__init__.py
We first assign 5 tasks created via create_tasks() to the task_list variable. As this occurs, we see the proper logging we added in tasks.py:
17:00:53 PM | INFO: Creating 5 tasks to be executed...
17:00:53 PM | INFO: Created Task: <Task pending name='Task #0' coro=<simple_coroutine() running at /Users/toddbirchard/Projects/asyncio-tutorial-part1/asyncio_intro_part1/coroutines.py:7>>
17:00:53 PM | INFO: Created Task: <Task pending name='Task #1' coro=<simple_coroutine() running at /Users/toddbirchard/Projects/asyncio-tutorial-part1/asyncio_intro_part1/coroutines.py:7>>
17:00:53 PM | INFO: Created Task: <Task pending name='Task #2' coro=<simple_coroutine() running at /Users/toddbirchard/Projects/asyncio-tutorial-part1/asyncio_intro_part1/coroutines.py:7>>
17:00:53 PM | INFO: Created Task: <Task pending name='Task #3' coro=<simple_coroutine() running at /Users/toddbirchard/Projects/asyncio-tutorial-part1/asyncio_intro_part1/coroutines.py:7>>
17:00:53 PM | INFO: Created Task: <Task pending name='Task #4' coro=<simple_coroutine() running at /Users/toddbirchard/Projects/asyncio-tutorial-part1/asyncio_intro_part1/coroutines.py:7>> The output of creating 5 tasks in tasks.py
We subsequently execute these five tasks via asyncio.wait(task_list). asyncio.wait() attempts to complete all the tasks in task_list and returns a tuple of "done" and "pending" tasks. Thanks to some added logging and the presence of task names, we can confirm all tasks completed successfully:
17:00:54 PM | INFO: Coroutine 0 has finished executing.
17:00:54 PM | INFO: Coroutine 1 has finished executing.
17:00:54 PM | INFO: Coroutine 2 has finished executing.
17:00:54 PM | INFO: Coroutine 3 has finished executing.
17:00:54 PM | INFO: Coroutine 4 has finished executing.
17:00:54 PM | SUCCESS: 5 tasks completed: ['Task #1', 'Task #4', 'Task #3', 'Task #0', 'Task #2']. Executing tasks with asyncio.wait()
Did You Get All That?
I pray that this tutorial has been somewhat helpful as a starting point for Asyncio. Part of the reason I haven't posted new content in a while is my inability to break these concepts into digestible pieces suitable for human consumption.
If you're stuck scratching your head, there's some good news. While I originally intended Asynchronous Python to be a single post, it quickly became evident that Asyncio is a long journey. Hooray for multi-part series' of dry, technical writing!
I'm aware I blew through the source code on this one, so I've uploaded a fully working version of this tutorial to Github below. It's yours to dig around in; here's to hoping the source code clears up any blind spots I might've missed:
 hackersandslackers
hackersandslackers


