

Redshift is quickly taking its place as the world's most popular solution for dumping obscene amounts of data into storage. It's nice to see good services flourish while clunky Hadoop-based stacks of yesterdecade suffer a long, painful death. Regardless of whether you're in data science, data engineering, or analysis, it's only a matter of time before all of us work with the world's most popular data warehouse.
While Redshift's rise to power has been deserved, the unanimous popularity of any service can cause problems... namely, the knowledge gaps that come with defaulting to any de facto industry solution. Most of us are locked into Redshift by default by merely being AWS customers. While we save time on researching and comparing solutions, this might come at the cost of answering some vital questions, such as "why Redshift?," or "how do I even get started with this thing?" If you're looking for some easily-to-digest mediocre answers, you've come to the right place.
Beneath The Hood
If you happen to be new to Redshift or data warehouses in general, you're in for a treat. If relational databases were Honda Civics, Redshift would be a Formula 1 race car. While Formula 1 machines might outperform your Honda by various metrics, the amount of upkeep and maintenance that goes into F1 racers would make it unsuitable for casual usage. Using Redshift effectively requires much more awareness of underlying database technologies than one would need to build a system which prioritizes ACID transactions.
When compared to traditional databases, data warehouses makes a ton of tradeoffs to optimize for the analysis of large amounts of data. Maintaining a Redshift cluster is a lot of work. Thus, it's essential to understand the pros and cons of Redshift before making such a big architectural decision (this notion has already been articulated by people more intelligent than I am).
Redshift Clustering
Every Redshift cluster is comprised of multiple machines, each of which only stores a fraction of our data. Each of these machines working in parallel to save and retrieve data, which adds a ton of complexity to how we should work with data.
Nodes which perform computations are called compute nodes. These nodes are managed by a leader node, which is responsible for managing data distribution and query execution amongst the other nodes.
Each compute node is actually split into multiple partitions themselves called slices. Depending on the size of nodes in your cluster, each compute node might support anywhere between 2-32 slices. Each slice is an individual partition containing a fraction of our dataset. Redshift performs best when slices have a close-to-equal distribution of data. When data is disproportionally distributed across slices, this phenomenon is called skew (we'll touch on how to optimize against skew in a bit).
Redshift can accommodate a variable number of machines in a cluster, thus making Redshift horizontally scalable, which is a key advantage. Redshift can scale outward almost infinitely which makes Redshift great for use cases where we need to query huge amounts of data in the realm of petabytes and beyond.
Column-oriented Database Management Systems
Redshift is great for data analysis, but we shouldn't use Redshift to power production-ready applications. To understand why one consideration would undoubtedly be the associated tradeoffs of columnar storage. Redshift is a column-oriented database management system, which means that our data is partitioned by column as opposed to row.
In a traditional database, rows are assigned an index to identify rows uniquely: retrieving a row by index will return the entirety of that row. A relational database with an index will perform significantly faster than a relational database without one because it's faster to query rows sorted logically. To understand why, imagine I asked you to try to find items in a messy garage. If I asked to find the "first 100 items I placed in here," it would be much easier to accomplish this had I first arranged everything in the order in which I added them to the garage.
Columnar databases trade the benefits of traditional indexing to solve a problem which becomes more significant with scale: the time of reading records from disk. If your tables have millions of rows and tons of columns, the mere act of retrieving entire rows creates a bottleneck. Partitioning data by column means that each time we retrieve a value from a partition, we're now only retrieving a single value per partition: this significantly reduces the load we put on the hard disk and results in overall faster speed across massive amounts of data.
When dealing with production-level information like user information or transactions, the data needed to keep an application running is relatively small. Applications should prioritize staying functional and minimizing loss of data while high volumes of database interactions take place. Data warehouses solve a different problem, which is allowing for analysis across tons of data in a performant manner, typically dealing with a small number of transactions at any given time.
A Note About Redshift Spectrum
Data is added to Redshift by first moving into a file stored in an S3 bucket as a static file (CSVs, JSON, etc). Once in S3, data can then be loaded into Redshift. This workflow of pipeline > S3 > Redshift is changed a bit by the introduction of Redshift Spectrum.
Unlike regular Redshift, Redshift Spectrum can directly query data stored across S3 buckets. This can make life a bit easier for people who don't necessarily want to write scripts for every piece of data that comes their way: it's a good way to sift through absurd amounts of historical data for ad-hoc requests. We won't be concerning ourselves too much with Redshift Spectrum for now.
Pricing
Redshift charges by uptime, with the smallest single-node cluster costing $0.25 per hour. Running a single-node cluster would be pointless, so it's pretty safe to assume any production Redshift cluster will cost at least 1 dollar per hour. That's a steep price for hobbyists just looking to learn the ropes. In practice, production Redshift clusters will easily break costs of hundreds of thousands of dollars per year.
It's clear from pricing alone that Redshift isn't intended for "hobbyists," thus it can actually be quite difficult to get up-to-speed with Redshift management unless a company happens to be paying the bill associated with you figuring out what you're doing.
Redshift's traditional pricing structure can be contrasted with competitors like Google BigQuery. BigQuery charges by size of each individual query, which allows companies of any size to start using a data warehouse before they can justify the costs of a dedicated cluster. Due to the fundamental technical differences between these solutions, Redshift will execute queries significantly faster than BigQuery, and the associated expenses reflect this.
Getting Started with Redshift
To get more intimately acquainted, we’ll quickly look at what the creation of a Redshift cluster looks like.
Like most things in AWS, getting started with Redshift kicks off with Amazon’s excruciating IAM permissions. Once we have a user with the proper permissions, we can move on to creating our cluster using Redshift’s "Quick Launch". Lastly, we’ll need to be sure we set the proper security groups to prevent our cluster from getting pillaged by the outside world.
Let's focus on what goes into creating a cluster:
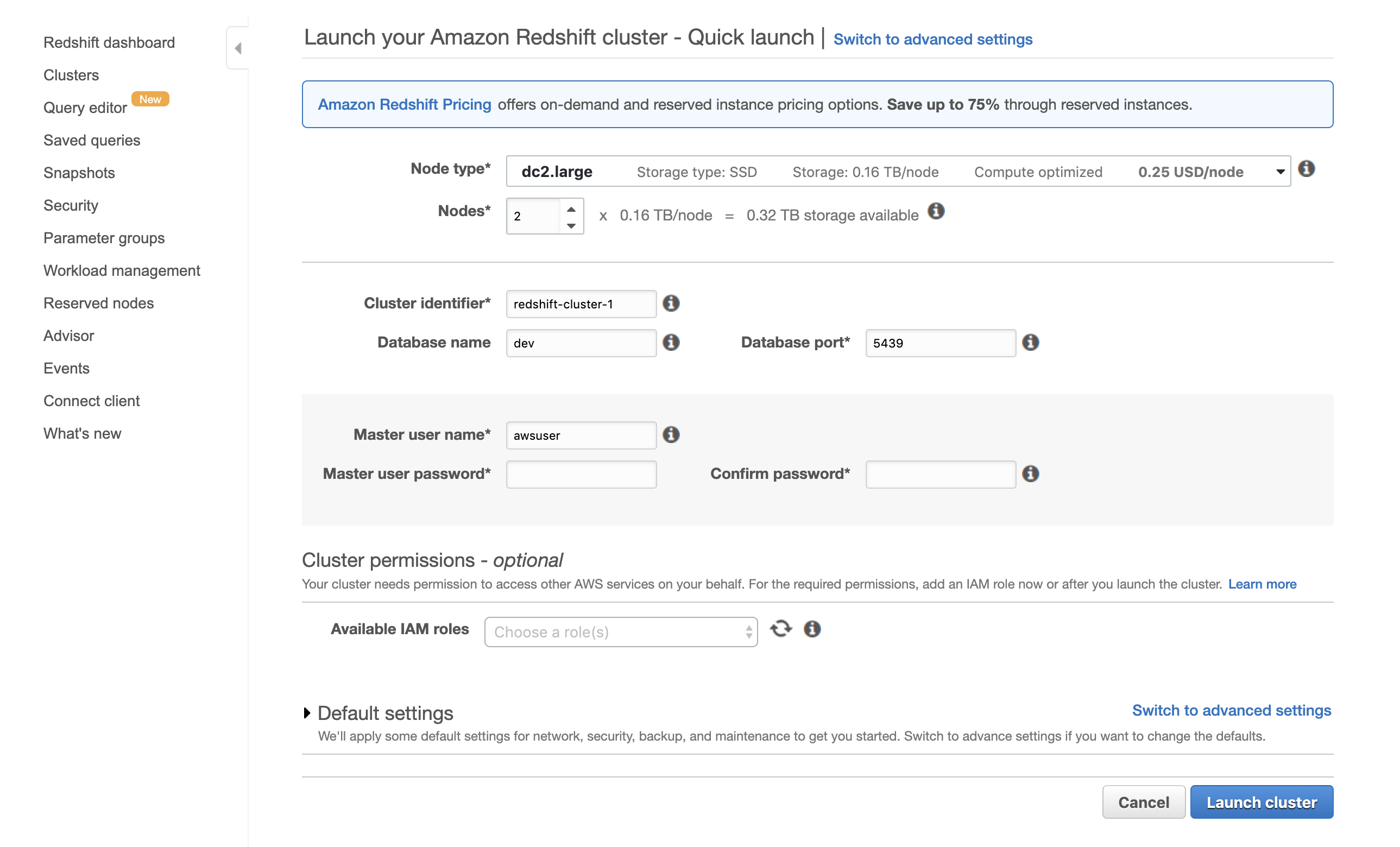
The default settings make creating a Redshift cluster easy. Aside from naming conventions and user-related options, all we need to do is select which type of node we want and the number of total nodes.
Loading Data Into Redshift
Redshift has two unique flavors for loading data: LOAD or COPY. Understanding the differences between these methods is a great way to wrap our head around how data warehouses work.
COPY
COPY is very much the preferred method for loading data: it’s a lightning-fast way of loading massive amounts of data into Redshift (which is our primary use case). Unlike INSERT, COPY is designed to load data en masse by utilizing parallel loading. When we move data into our cluster via COPY, each node in our cluster works in tandem to load from multiple sources at once (such as multiple files in an S3 bucket). Splitting incoming data amongst multiple files will result in faster load times with COPY.
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options] COPY accepts data from 4 types of sources: S3, EMR, Dynamo, or even directly from a machine via SSH. 3/4 of those options are AWS products, and I wouldn’t be surprised if this were done intentionally to incentivize customers to sticking to AWS architecture in order to utilize the superior optimization of COPY.
COPY by running an UNLOAD query. Using UNLOAD will load the results of a query into an S3 bucket like so: UNLOAD(“YOUR_QUERY”)
TO ‘S3_BUCKET_PATH’
AUTHORIZATION (BUCKET_AUTHORIZATION)INSERT
Then we have INSERT: a word that should look familiar from SQL. INSERT will always be slower than COPY, and data compression is rendered inefficient when loading data in this way. The most common use case for INSERT is when COPY is not an option.
INSERT INTO table_name [ ( column [, ...] ) ] {DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) [, ( { expression | DEFAULT } [, ...] ) [, ...] ] | query }Vacuum and Analyze After Adding Data
Redshift has a couple of housekeeping operations intended to run after adding or modifying massive amounts of data in Redshift: VACUUM and ANALYZE. Using VACUUM purges data marked for deletion, thus recovering space and allowing the sort order of records to be updated. VACUUM was previously an operation which needed to be run manually by a Redshift admin. Luckily for us, Redshift has since been updated to run VACUUM in the background automatically after manipulation. Regardless, we should be aware of what VACUUM does and when it is running.
VACUUM [ FULL | SORT ONLY | DELETE ONLY | REINDEX ] [ [ table_name ] [ TO threshold PERCENT ] ]To find records most efficiently during a query, Redshift looks at the statistical metadata of a given table to help determine where a record might be hiding. ANALYZE updates this metadata for a given table. The best time to run ANALYZE would be after a sizable percentage of a table has been modified.
ANALYZE [ VERBOSE ] [ [ table_name [ ( column_name [, ...] ) ] ] [ PREDICATE COLUMNS | ALL COLUMNS ]Table Distribution Styles
An important topic we should be aware of is table distribution styles. Distribution styles are set on tables upon creation and determine how rows will be distributed amongst slices in the cluster. Distribution style can be set to AUTO, EVEN, KEY, or ALL:
- ALL: A table with an ALL distribution will be replicated on every slice in the cluster. Since rows will live on all slices, Redshift won't need to hit all slices in a cluster to complete a query against a table with an ALL distribution. Setting an ALL distribution is best suited for tables with a small number of rows (thousands of rows).
- EVEN: Tables distributed with EVEN will have rows populated evenly across all slices in a cluster. EVEN lends itself well to tables which won't be joined.
- KEY: Rows are distributed across slices based on a distribution key, where rows sharing a key value will be guaranteed to live on the same slice (we'll look at how to set distribution keys in the next section).
- AUTO: An AUTO distribution is usually the safest distribution style as it allows Redshift to dynamically manage a table's distribution style. Redshift selects the inferred best distribution based on the contents of the table and knows to change the distribution style automatically when contents of the table change dramatically (Redshift automatically gives small tables an ALL distribution and changes the style to EVEN when a significant number of rows are added).
Indexing and Keys
Unlike traditional databases, Redshift doesn't support indexes. Instead, Redshift uses sort keys and dist keys to aid in the organization and retrieval of rows.
Sort Keys
By setting a sort key on a table, we're telling Redshift that the values in this column are a useful indicator for finding data within a table. If you think back to algorithms 101, it's easy to imagine how dealing with sorted data would be beneficial to a search query, similar to finding values in a sorted array versus an unsorted array. As a result, how you set you sort keys will have a significant effect on how quickly your queries will be able to execute.
How you define your sort keys should differ depending on how you plan on querying your data. Setting nonsensical sort keys on your data will actually slow your queries down, as Redshift attempts to make sense of finding data via some worthless indicator. Try to set sort keys based on columns which can 1) be sorted in such a way that is coherent, and 2) are useful to the way in which you're expecting to query your data. Sort keys can only be set during table creation, so it's important to try and get this right off the bat:
CREATE TABLE automobile_sales (
model_number INTEGER,
sold_at timestamp
) SORTKEY(model_number);It's extremely important to always cognizant of how Redshift is expecting to look for data, whether you're creating your tables or querying existing tables which already have their sort keys determined.
Distribution Keys
In the above example, we sorted a table named automobile_sales by a column named model_number (a "model number" would presumably be an ID which represents the type of car sold). Since we're working data which is distributed across multiple machines, there's a very real possibility that rows with the same model number will be saved to different nodes in our cluster. If we were able to explicitly bunch together rows with the same model number on the same cluster nodes, it would be much easier to find records which had the model number for a Ford Taurus, because we'd be telling Redshift that all records for Ford Tauruses live on node A (or whatever).
Distribution keys tell Redshift to store all rows which share the value in a column on the same machine to improve query performance. Without a distribution key present, Redshift would be forced to hit every machine in our cluster and perform and aggregation to see if Ford Tauruses exist on each machine. To prevent this from happening, we can set an additional distribution key on our sort key:
CREATE TABLE automobile_sales (
model_number INTEGER,
sold_at timestamp
) DISTKEY(model_number) SORTKEY(model_number);What if 90% of all automobiles sold happen to be the same model? That would suddenly make model_number a weak candidate for a sort key/distribution key since all these rows would be bottlenecked to a single machine. This disproportionate distribution of data across slices referred to as skew. To visualize how skew affects query time negatively, check out the performance of a query on a badly skewed Redshift cluster:
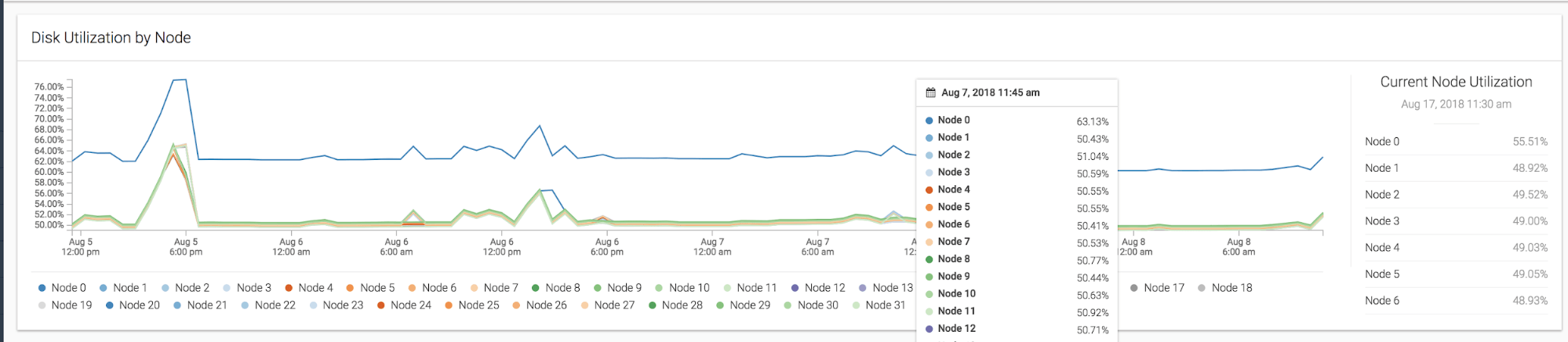
We can see clearly that Node 0 is bottlenecking our entire query by taking the majority of a query's load while the other nodes site idle. This is why it's important to consider how evenly distributed our data will be when we're deciding on distribution keys.
In our automobile_sales example, we could instead rely on something more evenly distributed, like the date of transactions:
CREATE TABLE automobile_sales (
model_number INTEGER,
sold_at timestamp
) DISTKEY(sold_at) SORTKEY(sold_at);Setting useful sort keys and distribution keys is very much dependent on your data set and how you plan to interact with said data. There are no one-size-fits-all answers in Redshift. Performance tuning is a continually moving target where only you can determine works best for your data. I recommend investigating query execution time and experimenting with different sort key/distribution key combos using Redshift's performance tools.
Constraints
Redshift shares the same concepts of unique keys, primary keys, and foreign keys from relational databases, but these keys exist strictly for informational purposes. Redshift will not actually enforce the uniqueness of unique keys, which are intended to be enforced by whichever layer exists in your ETL pipeline before Redshift.
Interestingly, the presence of these keys does help Redshift infer things about your data during queries, which can help in the execution of queries such as those which involve a SELECT DISTINCT clause. It's worth noting that setting primary or unique keys on columns which don't actually contain unique values can result in queries returning incorrect results.
Further Optimizing Redshift
To continue optimizing the performance of your Redshift queries, AWS actually provides a useful query in their documentation to inspect your tables:
SELECT SCHEMA schemaname,
"table" tablename,
table_id tableid,
size size_in_mb,
CASE
WHEN diststyle NOT IN ('EVEN','ALL') THEN 1
ELSE 0
END has_dist_key,
CASE
WHEN sortkey1 IS NOT NULL THEN 1
ELSE 0
END has_sort_key,
CASE
WHEN encoded = 'Y' THEN 1
ELSE 0
END has_col_encoding,
CAST(max_blocks_per_slice - min_blocks_per_slice AS FLOAT) / GREATEST(NVL (min_blocks_per_slice,0)::int,1) ratio_skew_across_slices,
CAST(100*dist_slice AS FLOAT) /(SELECT COUNT(DISTINCT slice) FROM stv_slices) pct_slices_populated
FROM svv_table_info ti
JOIN (SELECT tbl,
MIN(c) min_blocks_per_slice,
MAX(c) max_blocks_per_slice,
COUNT(DISTINCT slice) dist_slice
FROM (SELECT b.tbl,
b.slice,
COUNT(*) AS c
FROM STV_BLOCKLIST b
GROUP BY b.tbl,
b.slice)
WHERE tbl IN (SELECT table_id FROM svv_table_info)
GROUP BY tbl) iq ON iq.tbl = ti.table_id;This query returns beneficial high-level information about your tables, such as which keys exist and how your data distribution is skewed. For the sole purpose of identifying skew, this query might be even more helpful:
SELECT
trim(pgn.nspname) AS SCHEMA,
trim(a.name) AS TABLE,
id AS tableid,
decode(pgc.reldiststyle, 0, 'even', 1, det.distkey, 8, 'all') AS distkey,
dist_ratio.ratio::decimal (10,
4) AS skew,
det.head_sort AS "sortkey",
det.n_sortkeys AS "#sks",
b.mbytes,
decode(b.mbytes, 0, 0, ((b.mbytes / part.total::decimal) * 100)::decimal (5, 2)) AS pct_of_total,
decode(det.max_enc, 0, 'n', 'y') AS enc,
a.rows,
decode(det.n_sortkeys, 0, NULL, a.unsorted_rows) AS unsorted_rows,
decode(det.n_sortkeys, 0, NULL, decode(a.rows, 0, 0, (a.unsorted_rows::decimal (32) / a.rows) * 100))::decimal (5,
2) AS pct_unsorted
FROM (
SELECT
db_id,
id,
name,
sum(ROWS) AS ROWS,
sum(ROWS) - sum(sorted_rows) AS unsorted_rows
FROM
stv_tbl_perm a
GROUP BY
db_id,
id,
name) AS a
JOIN pg_class AS pgc ON pgc.oid = a.id
JOIN pg_namespace AS pgn ON pgn.oid = pgc.relnamespace
LEFT OUTER JOIN (
SELECT
tbl,
count(*) AS mbytes
FROM
stv_blocklist
GROUP BY
tbl) b ON a.id = b.tbl
INNER JOIN (
SELECT
attrelid,
min(
CASE attisdistkey
WHEN 't' THEN
attname
ELSE
NULL
END) AS "distkey",
min(
CASE attsortkeyord
WHEN 1 THEN
attname
ELSE
NULL
END) AS head_sort,
max(attsortkeyord) AS n_sortkeys,
max(attencodingtype) AS max_enc
FROM
pg_attribute
GROUP BY
1) AS det ON det.attrelid = a.id
INNER JOIN (
SELECT
tbl,
max(mbytes)::decimal (32) / min(mbytes) AS ratio
FROM (
SELECT
tbl,
trim(name) AS name,
slice,
count(*) AS mbytes
FROM
svv_diskusage
GROUP BY
tbl,
name,
slice)
GROUP BY
tbl,
name) AS dist_ratio ON a.id = dist_ratio.tbl
JOIN (
SELECT
sum(capacity) AS total
FROM
stv_partitions
WHERE
part_begin = 0) AS part ON 1 = 1
WHERE
mbytes IS NOT NULL
ORDER BY
mbytes DESC;We could spend all week getting into Redshift performance tuning, but I think we've covered enough ground for an intro-to-Redshift post (to say the least).



