

You may have heard me drone on here and there about MongoDB Atlas and MongoDB Stitch. Previously, I hacked together an awful workflow that somehow utilized Tableau as an ETL tool to feed JIRA information into Mongo. I'd like to formally apologize for that entire series: I can't imagine there's a single soul on this planet interested in learning about all of those things simultaneously. Such hobbies reserved for masochists with blogging addictions. I apologize. Let's start over.
This is not a tutorial on how to use MongoDB: the database. I have zero interest cluttering the internet by reiterating what a MEAN stack is for the ten thousandth time, nor will I bore you with core NoSQL concepts you already understand. I'm here to talk about the giant on the horizon we didn't see coming, where MongoDB the database decided to become MongoDB Inc: the enterprise cloud provider. The same MongoDB that recently purchased mLab, the other cloud-hosted solution for Mongo databases. MongoDB the company is bold enough to place its bets on building a cloud far simpler and restricted than AWS or Google Cloud. The core of that bet implies that most of us aren't exactly building unicorn products as much as we're reinventing the wheel: and they're probably right.
Welcome to our series on MongoDB cloud, where we break down every service MongoDB has to offer; one by one.
What is MongoDB Cloud, and Does it Exist?
What I refer to as "MongoDB Cloud" (which, for some reason, isn't the actual name of the suite MongoDB offers) is actually two products:
- MongoDB Atlas: A cloud-hosted MongoDB cluster with a beefy set of features. Real-time dashboards, high-availability, security features, an awesome desktop client, and a CLI to top it all off.
- MongoDB Stitch: A group of services designed to interact with Atlas in every conceivable way, including creating endpoints, triggers, user authentication flows, serverless functions, and a UI to handle all of this.
Atlas as a Standalone Database
There are plenty of people who simply want an instance of MongoDB hosted in the cloud as-is: just ask the guys at mLab. This was in fact how I got pulled into Mongo's cloud myself.
MongoDB Atlas has plenty of advantages over a self-hosted instance of Mongo, which Mongo itself is confident in by offering a free tier of Atlas to prospective buyers. If you're a company or enterprise, the phrases High Availability, Horizontal Scalability, relatively Higher Performance will probably be enough for you. But for us hobbyists, why pay for a Mongo cloud instance?
Mongo themselves gives this comparison:
| Overview | MongoDB Atlas | Compose | ObjectRocket |
|---|---|---|---|
| Free Tier |
Yes Storage: 512 MB RAM: Variable |
No 30-day free trial |
No 30-day free trial |
| Live migration |
Yes |
No |
No |
| Choice of cloud providers | AWS, Azure & GCP |
AWS, Softlayer & GCP Available in 2 regions for each provider |
Rackspace |
| Choice of instance configuration | Yes |
No Configuration based on required storage capacity only. No way to independently select underlying hardware configurations |
No Configuration based on required storage capacity only. No way to independently select underlying hardware configurations |
| Availability of latest MongoDB version |
Yes New versions of the database are available on MongoDB Atlas as soon as they are released |
No New versions typically available 1-2 quarters following database release |
No New versions typically available 1-2 quarters following database release |
| Replica Set Configuration |
Up to 7 replicas All replicas configured as data-bearing nodes |
3 data-bearing nodes One of the data-bearing nodes is hidden and used for backups only |
3 data-bearing nodes |
| Automatic Sharding Support |
Yes |
No |
Yes |
| Data explorer |
Yes |
Yes |
No |
| SQL-based BI Connectivity |
Yes |
No |
No |
| Pause and resume clusters |
Yes |
No |
No |
| Database supported in on-premise deployments |
Yes MongoDB Enterprise Advanced |
No |
No |
| Global writes Low-latency writes from anywhere in the world | Yes | No | No |
| Cross-region replication Distribute data around the world for multi-region fault tolerance and local reads | Yes | No | No |
| Monitoring of database health with automated alerting |
Yes MongoDB Atlas UI & support for APM platforms (New Relic) |
Yes New Relic |
Yes New Relic |
| Continuous backup |
Yes Backups maintained seconds behind production cluster |
No Backups taken with mongodump against hidden replica set member |
No Backups taken with mongodump |
| Queryable backups |
Yes |
No |
No |
| Automated & consistent snapshots of sharded clusters |
Yes |
Not Applicable No support for auto-sharding |
No Requires manually coordinating the recovery of mongodumps across shards |
| Access control & IP whitelisting |
Yes |
Yes |
Yes |
| AWS VPC Peering |
Yes |
Beta Release |
Yes Additional Charge |
| Encryption of data in-flight |
Yes TLS/SSL as standard |
Yes |
Yes |
| Encryption of data at-rest |
Yes Available for AWS deployments; always on with Azure and GCP |
No |
Yes Available only with specific pricing plans and data centers |
| LDAP Integration | Yes |
No |
No |
|
Database-level auditing Track DDL, DML, DCL operations |
Yes |
No |
No |
| Bring your own KMS | Yes |
No |
No |
Realistically there are probably only a number of items that stand out on the comparison list when we go strictly database-to-database. Freedom over instance configuration sounds great, but in practice is more similar to putting a cap on how much MongoDB decides to charge you that month (by the way, it's usually a lot; keep this mind). Having the Latest Version seems great, but this can just as easily mean breaking production unannounced as much as it means new features.
MongoDB clearly wins over the enterprise space with Continuous & queryable backups, integration with LDAP, and automatic sharding support. Truthfully if this were merely a database-level feature and cost comparison, the decision to go with MongoDB Atlas would come down to how much you like their pretty desktop interface:
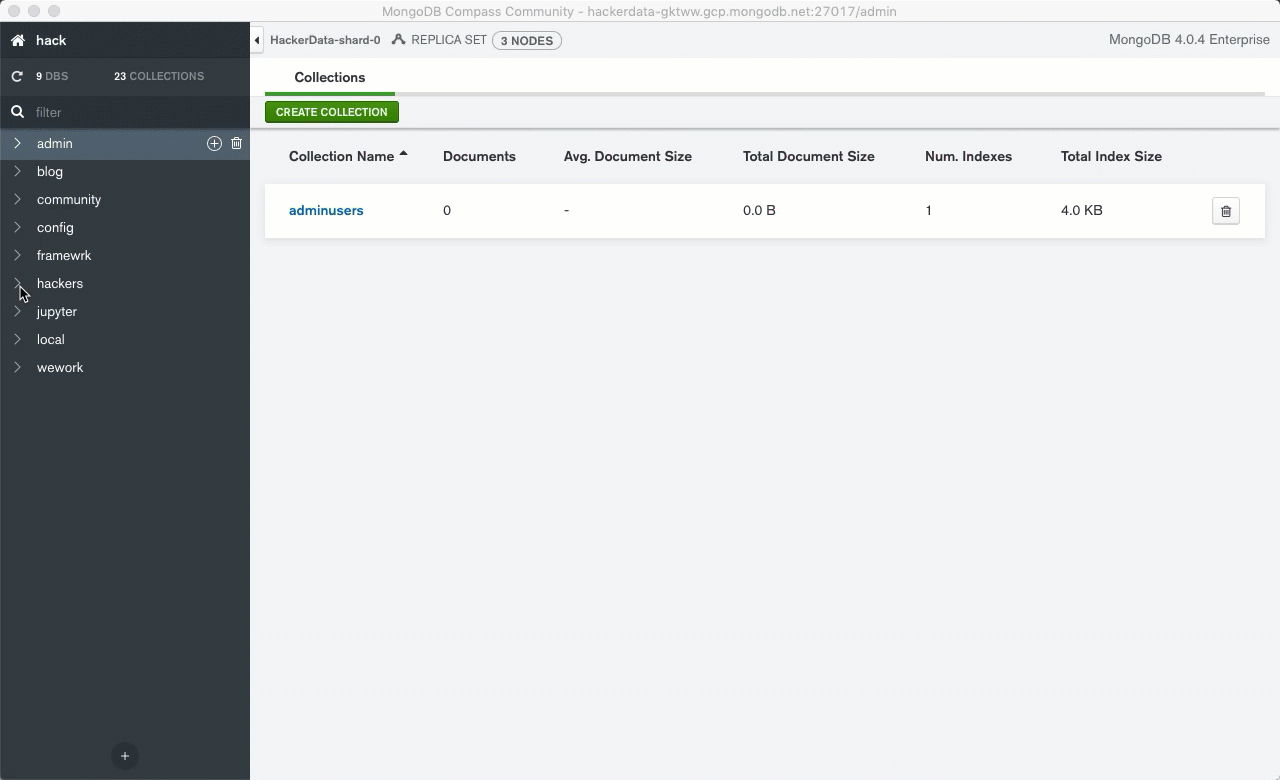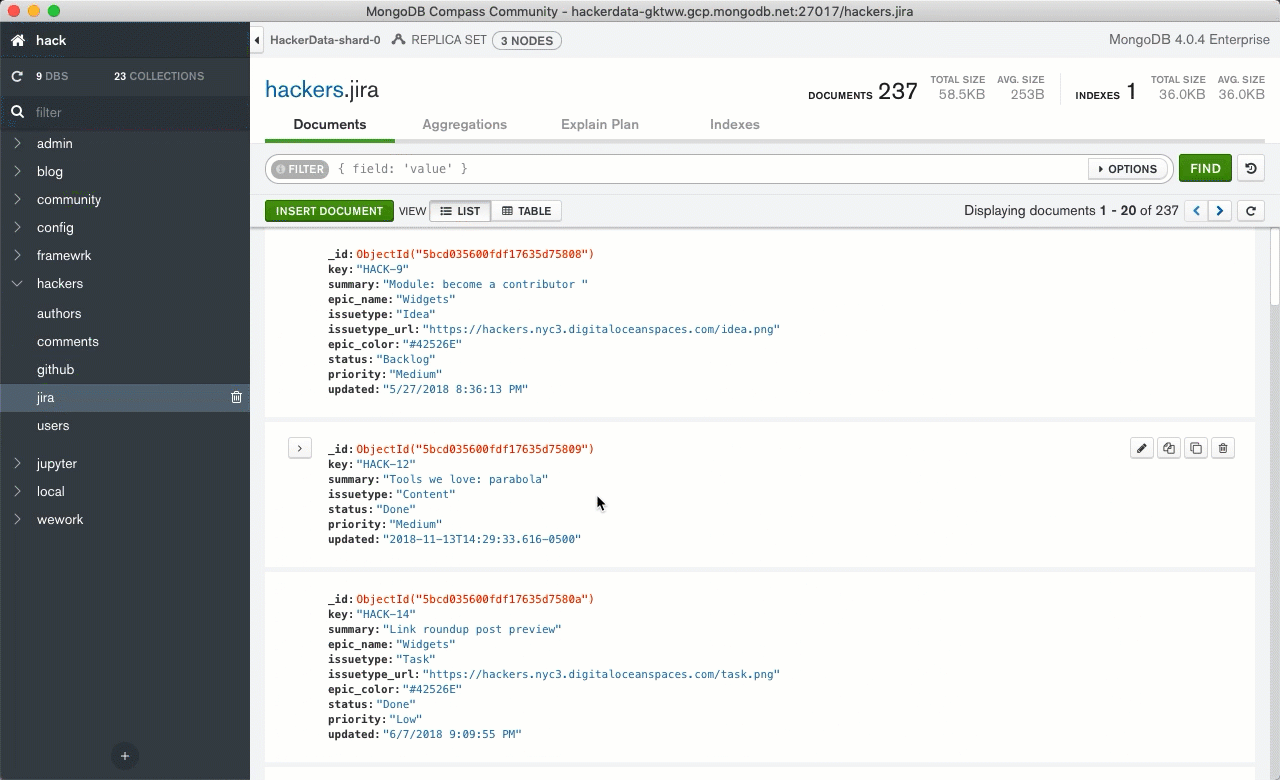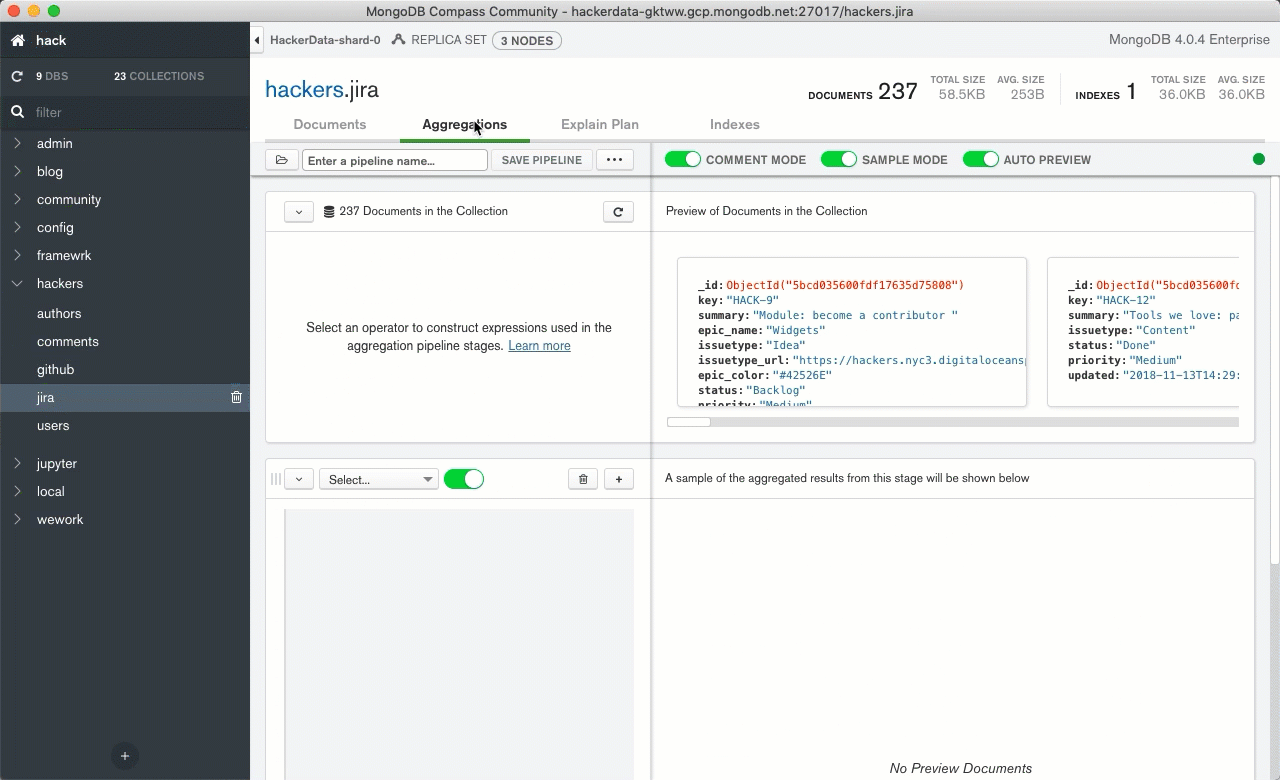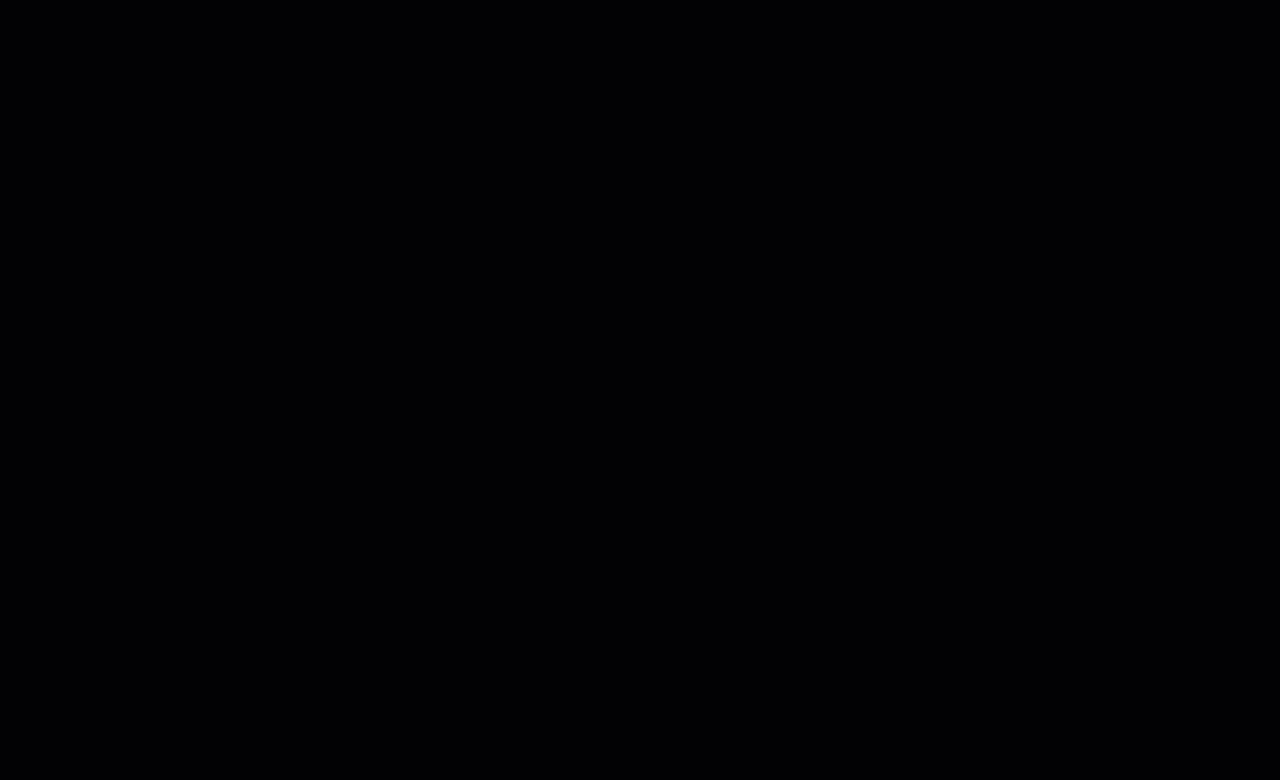
So let's say MongoDB Atlas is marginally better than a competitor in the confined realm of "being a database." Are Stitch microservices enough to justify keeping your instance with the MongoDB team?
Service-by-Service Breakdown of Stitch
Stitch is kind of like if AWS exited in an alternative universe, where JSON and JavaScript were earth's only technologies. Thinking back to how we create APIs in AWS, the status quo almost always involves spinning up a Dynamo (NoSQL) database to put behind Lambda functions, accessible by API Gateway endpoints. Stitch's core use case revolves around this use-case of end-user-accessing-data, with a number of services dedicated specifically to supporting or improving this flow. The closest comparison to Stitch would be GCloud's Firebase.
So what makes Stitch so special?
Service 1: Querying Atlas Securely via Frontend Code
Something that cannot be understated is the ability to query Atlas securely via frontend Javascript. We're not passing API keys, Secrets, or any sort of nonsense; because you've configured things correctly, whitelisted domains can run queries of any complexity without ever interacting with an app's backend. This is not a crazy use case: consider this blog for example.
Let's get started with some boilerplate Javascript. This will demonstrate uploading a 'user' document, and querying for the result. Here's what that looks like for anybody who wants to dump their scripts inline with HTML:
<script src="https://s3.amazonaws.com/stitch-sdks/js/bundles/4.0.8/stitch.js"></script>
<script>
const client = stitch.Stitch.initializeDefaultAppClient('myapp');
const db = client.getServiceClient(stitch.RemoteMongoClient.factory, 'mongodb-atlas').db('<DATABASE>');
client.auth.loginWithCredential(new stitch.AnonymousCredential()).then(user =>
db.collection('<COLLECTION>').updateOne({owner_id: client.auth.user.id}, {$set:{number:42}}, {upsert:true})
).then(() =>
db.collection('<COLLECTION>').find({owner_id: client.auth.user.id}, { limit: 100}).asArray()
).then(docs => {
console.log("Found docs", docs)
console.log("[MongoDB Stitch] Connected to Stitch")
}).catch(err => {
console.error(err)
});
</script>Alternatively, if you're using NPM, install it as such:
npm install --save mongodb-stitch-browser-sdk@"^4.3.1"In that case, your equivalent Javascript will look like this:
const {
Stitch,
RemoteMongoClient,
AnonymousCredential
} = require('mongodb-stitch-browser-sdk');
const client = Stitch.initializeDefaultAppClient('');
const db = client.getServiceClient(RemoteMongoClient.factory, 'hackers-api').db('<DATABASE>');
client.auth.loginWithCredential(new AnonymousCredential()).then(user =>
db.collection('<COLLECTION>').updateOne({owner_id: client.auth.user.id}, {$set:{number:42}}, {upsert:true})
).then(() =>
db.collection('<COLLECTION>').find({owner_id: client.auth.user.id}, { limit: 100}).asArray()
).then(docs => {
console.log("Found docs", docs)
console.log("[MongoDB Stitch] Connected to Stitch")
}).catch(err => {
console.error(err)
});This isn't to say we're allowing any user to query any data all willy-nilly just because they're on our whitelisted IP: all data stored in Atlas is restricted to specified Users by defining User Roles. Joe Schmoe can't just inject a query into any presumed database and wreak havoc, because Joe Schmoe can only access data we've permitted his user account to view or write to. What is this "user account" you ask? This brings us to the next big feature...
Service 2: End-User Account Creation & Management
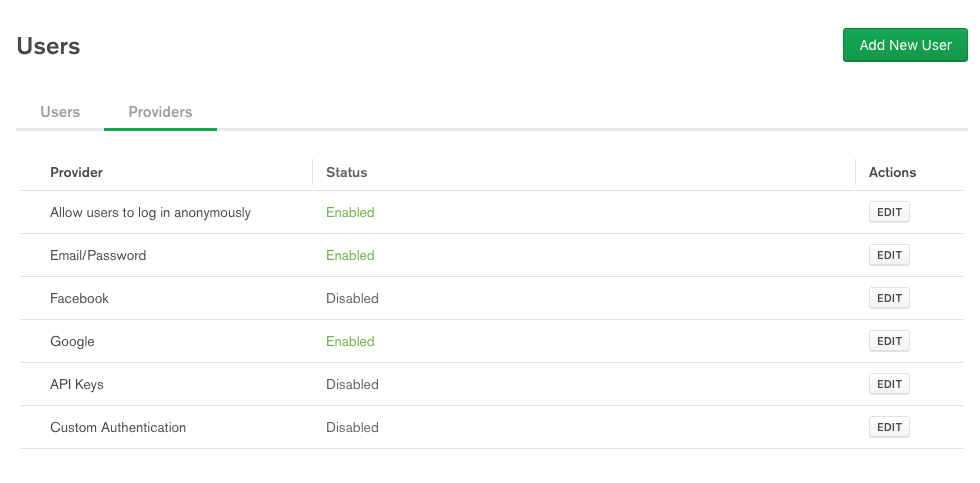
Creating an app with user accounts is a huge pain in the ass. Cheeky phrases like 'Do the OAuth Dance' can't ever hope to minimize the agonizing repetitive pain of creating user accounts or managing relationships between users and data (can user X see a comment from user Y?). Stitch allows most of the intolerably benign logic behind these features to be handled via a UI.
It would be a far cry to say these processes have been "trivialized", but the time saved is perhaps just enough to keep a coding hobbyist interested in their side projects as opposed to giving up and playing Rocket League.
As far as the permissions to read comments go... well, here's a self-explanatory screenshot of how Stitch handles read/write document permission in its simplest form:
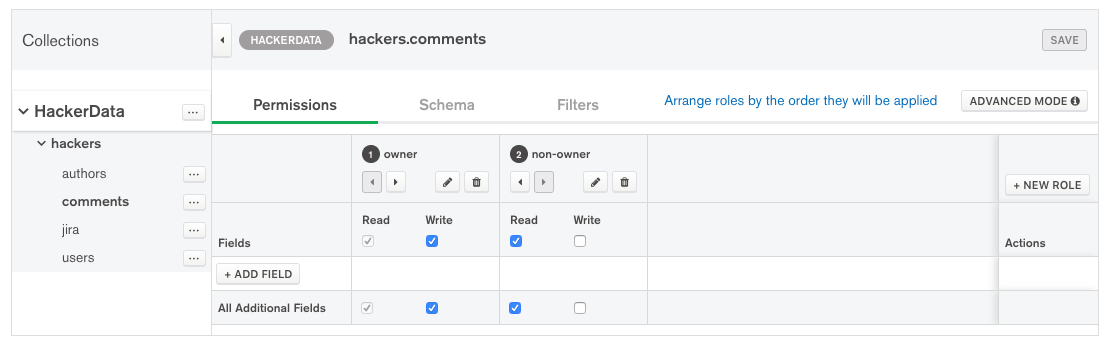
Service 3: Serverless Functions
Stitch functions are akin to AWS Lambda functions, but much easier to configure for cross-service integration (and also limited to JavaScript ECMA 2015 or something). Functions benefit from the previous two features, in that they too can be triggered from a whitelisted app's frontend, and are governed by a simple "rules" system, eliminating the need for security group configurations etc.
This is what calling a function from an app's frontend looks like:
<script>
client.auth.loginWithCredential(new stitch.AnonymousCredential()).then(user => {
client.callFunction("numCards", ["In Progress"]).then(results => {
$('#progress .count').text(results + ' issues');
})
});
</script>Functions can run any query against Atlas, retrieve values (such as environment variables), and even call other functions. Functions can also be fired by database triggers, where a change to a collection will prompt an action such as an alert.
Service 4: HTTP Webhooks
Webhooks are a fast way to toss up endpoints. Stitch endpoints are agnostic to one another in that they are one-off URLs to perform single tasks. We could never build a well-designed API using Stitch Webhooks, as we could with API Gateway; this simply isn't the niche MongoDB is trying to hit (the opposite, in fact).
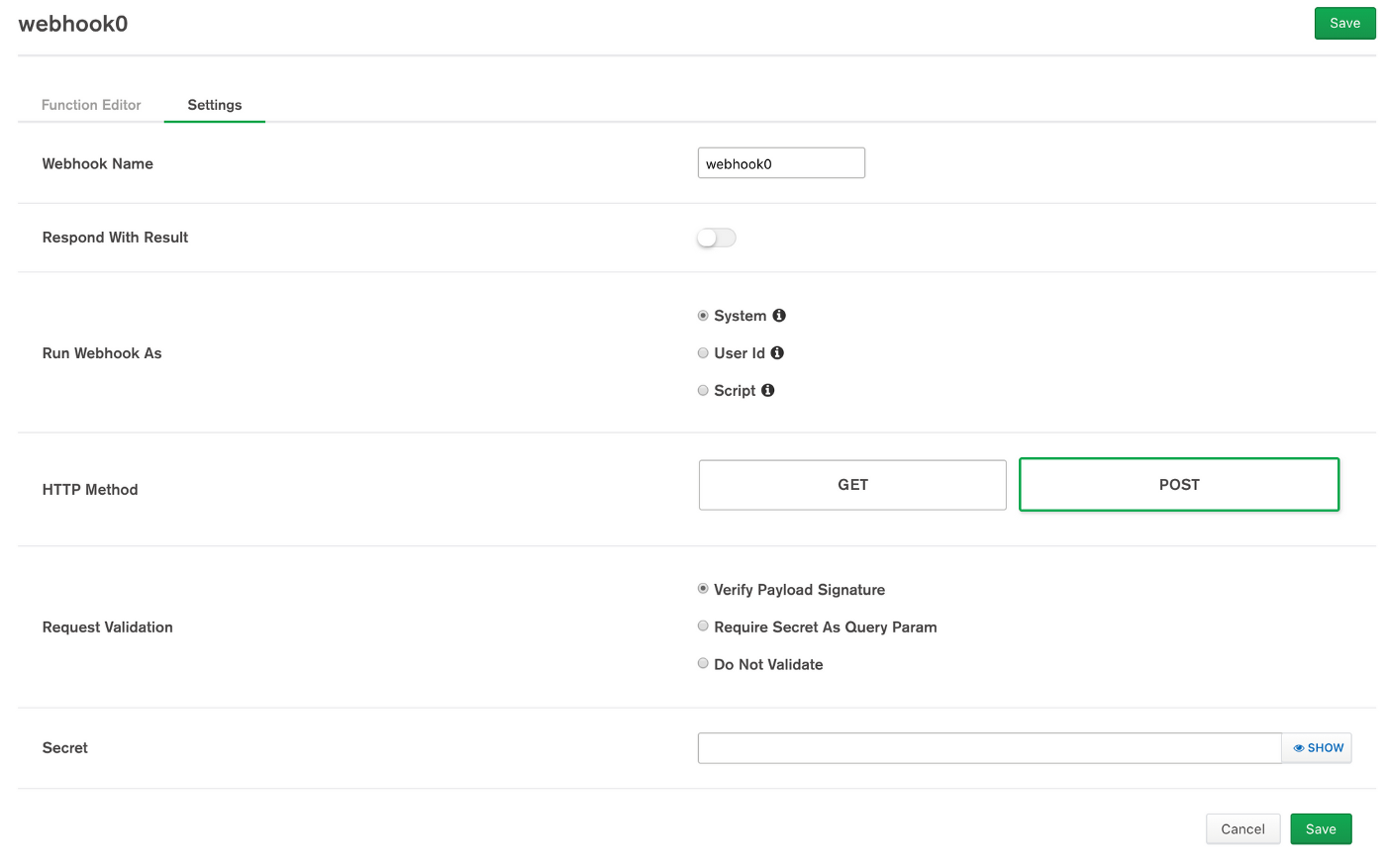
This form with a mere 6 fields clearly illustrates what Stitch intends to do: trivializing the creation of traditionally non-trivial features.
Service 5: Storing 'Values' in Stitch
A "value" is equivalent to an environment variable. These can be used to store API keys, secrets, or whatever. Of course, values are retrieved via functions.
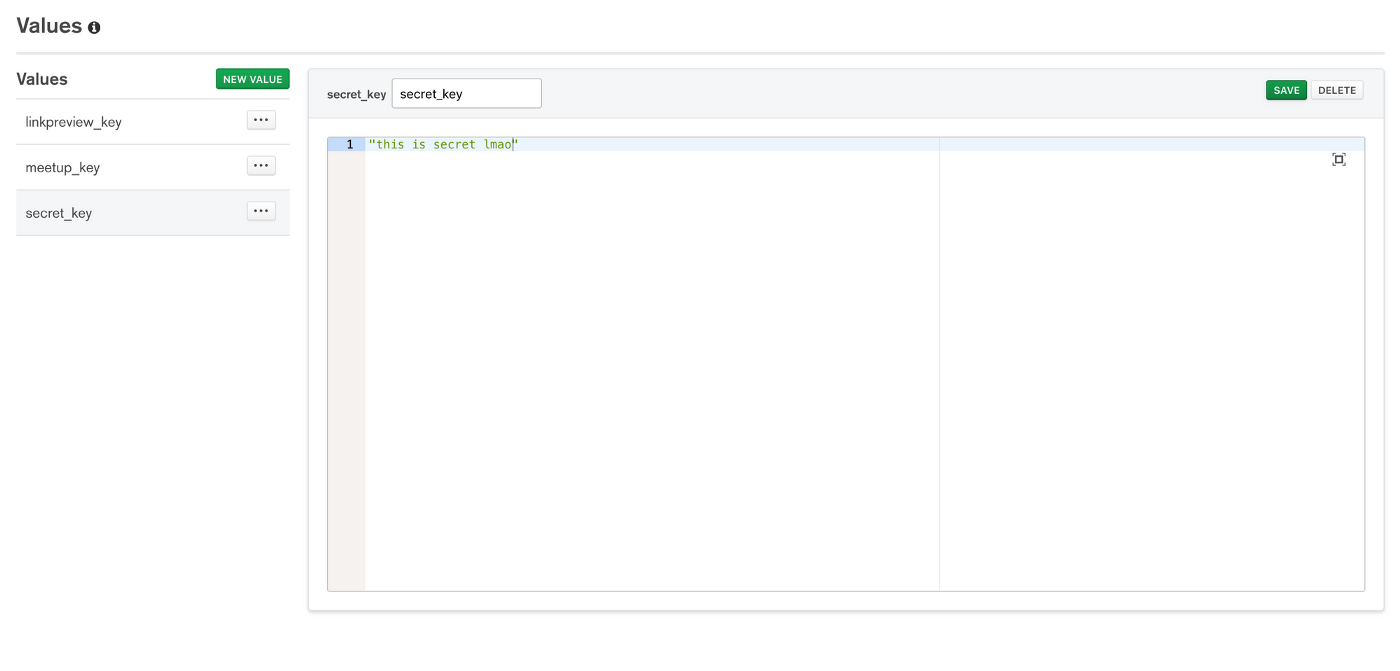
Service 6+: A Bunch of Mostly Bloated Extras
Finally, Stitch has thrown in a few third-party integrations for good measure. Some integrations like S3 Integration could definitely come in handy, but it's worth asking why Mongo constantly over advertises their integrations with Github and Twilio. We've already established that we can create endpoints which accept information, and we can make functions which GET information... so isn't anything with an API pretty easy to 'integrate' with?
This isn't to say the extra services aren't useful, they just seem a bit... odd. It feels a lot like bloating the catalog, but the catalog isn't nearly bloated enough where it feels normal (like Heroku add-ons, for example). The choice to launch Stitch with a handful of barely-useful integrations only comes off as more and more aimless as time passes; as months turn to years and no additions or updates are made to service offerings, it's worth questioning what the vision had been for the product in the first place. In my experience, feature sets like these happen when Product Managers are more powerful than they are useful.
The Breathtaking Climax: Is Stitch Worth It?
I've been utilizing Stitch to fill in the blanks in development for months now, perhaps nearly a year. Each time I find myself working with Stitch or looking at the bill, I can't decide if it's been a Godsend for its corner of the market, or an expensive toy with an infuriating lack of accurate documentation.
Stitch is very much a copy-and-paste-cookie-cutter-code type of product, which begs the question of why their tutorials are recklessly outdated; sometimes to the point where MongoDB's own tutorial source code doesn't work. There are so many use cases and potential benefits to Stitch, so why is the Github repo containing example code snippets so unmaintained, and painfully irrelevant? Lastly, why am I selling this product harder than their own internal team?
Stitch is a good product with a lot of unfortunate oversight. That said, Google Firebase still doesn't even have an "import data" feature, so I suppose it's time to dig deep into this vendor lock and write a 5-post series about it before Silicon Valley's best and brightest get their shit together enough to actually create something useful and intuitive for other human beings to use. In the meantime, feel free to steal source from tutorials I'll be posting, because they'll be sure to, you know, actually work.



