

Data engineering technology stacks have a relatively sizeable amount of variance across companies. Depending on the skills and languages preferred by a company's developers, a data stack might be anything between a heavily Java shop, or a Python shop relying on PySpark. Despite the lack of a prescribed "industry-standard" stack, it's becoming clear that one thing will likely be shared by all next-generation data organizations with high-throughput: Apache Kafka.
Kafka is the go-to centerpiece for organizations dealing with massive amounts of data in real-time. Kafka is designed to process billions (or even trillions) of data events per day; a feat which aligns well with its original use case of handling every action taken on LinkedIn. Kafka has since been open-sourced, and can now be used by regular losers who don't work at LinkedIn... like you and me!
Breaking Down Kafka
Kafka is middleware where data comes in and then goes out... it's as simple as that! Perhaps think of it as a CPU to our data workflow: it sits in the center of our pipelines, ingesting and outputting data to the final systems where they belong. You might think: why is something so simple considered to be so important?
Somehow we've made it this far as a specifies - 14 years since Hadoop was invented, no less - before anybody thought it would be a good idea to centralize the flow of data in one place.
Kafka Terminology
Time to get familiar with some of Kafka's vocabulary:
- Producers: A "producer" is a source of inbound data. Producers might be servers outputting logs, IOT devices transmitting information, a script transforming data, or anything which is always spitting out data.
- Topics: When producers toss data into Kafka, the data belongs to one of many available "topics," which is our way of grouping related data together to be processed. Topics themselves are logs of continually growing data feeds, where data is stored in a simple key/value format. Data pouring in from producers gets added messages at the end of the log: this is known as a queue (similar to Redis, or any other queue system).
- Messages: A "message" is a key/value pair of data. The word is a little misleading but is pretty standard for queue-based systems.
- Consumers: Consumers ingest the data provided by producers. A consumer is a final destination where data is stored, such as a database or data warehouse.
- Partitions: Topics can be split into "partitions". Partitioning a topic allows it to be split across multiple machines, thus making Kafka obscenely scalable. We'll get more into that in a moment.
Benefits of Kafka and/or Message Queues
Let's make a quick comparison to see why Kafka provides value to a typical data stack. First, let's look at an example of what might be happening at a company without Kafka:
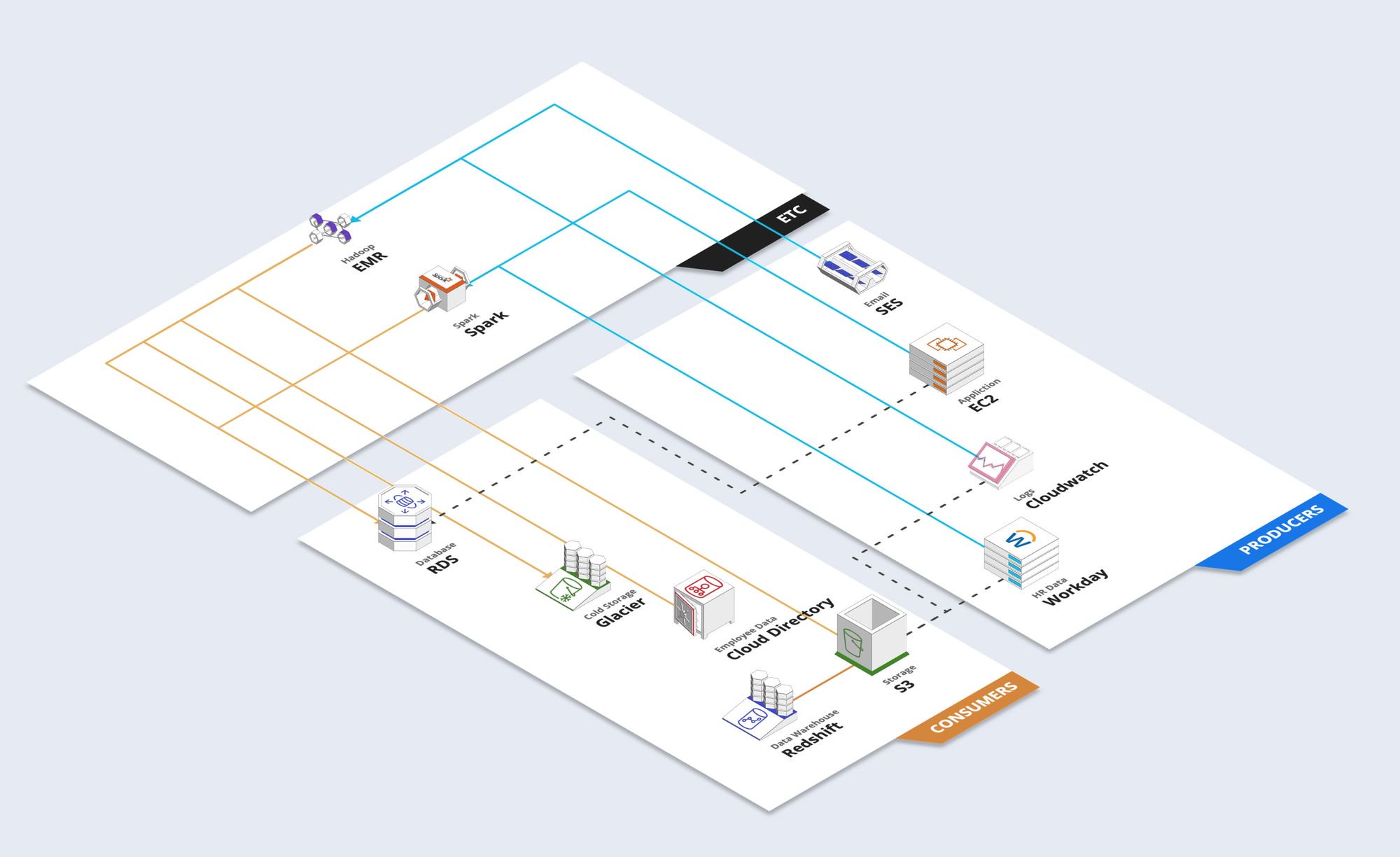
If I were to ask you to tell me which producers were writing to Redshift, would you be able to? Of course not! The chart above is unreadable because the architecture of the above is a mess. I know the above is a realistic scenario because I've worked at companies where this is happening.
Consider the fact that the vast majority of companies haven't even documented their data flows as thoroughly as the above (which is an awful truth). If something goes wrong, how do you diagnose what happened? How do you know which source the data came from? If you're new on the job, how do you begin to figure out what the hell is going on when everybody is too busy to speak to you?
Let's try this again, with Kafka:
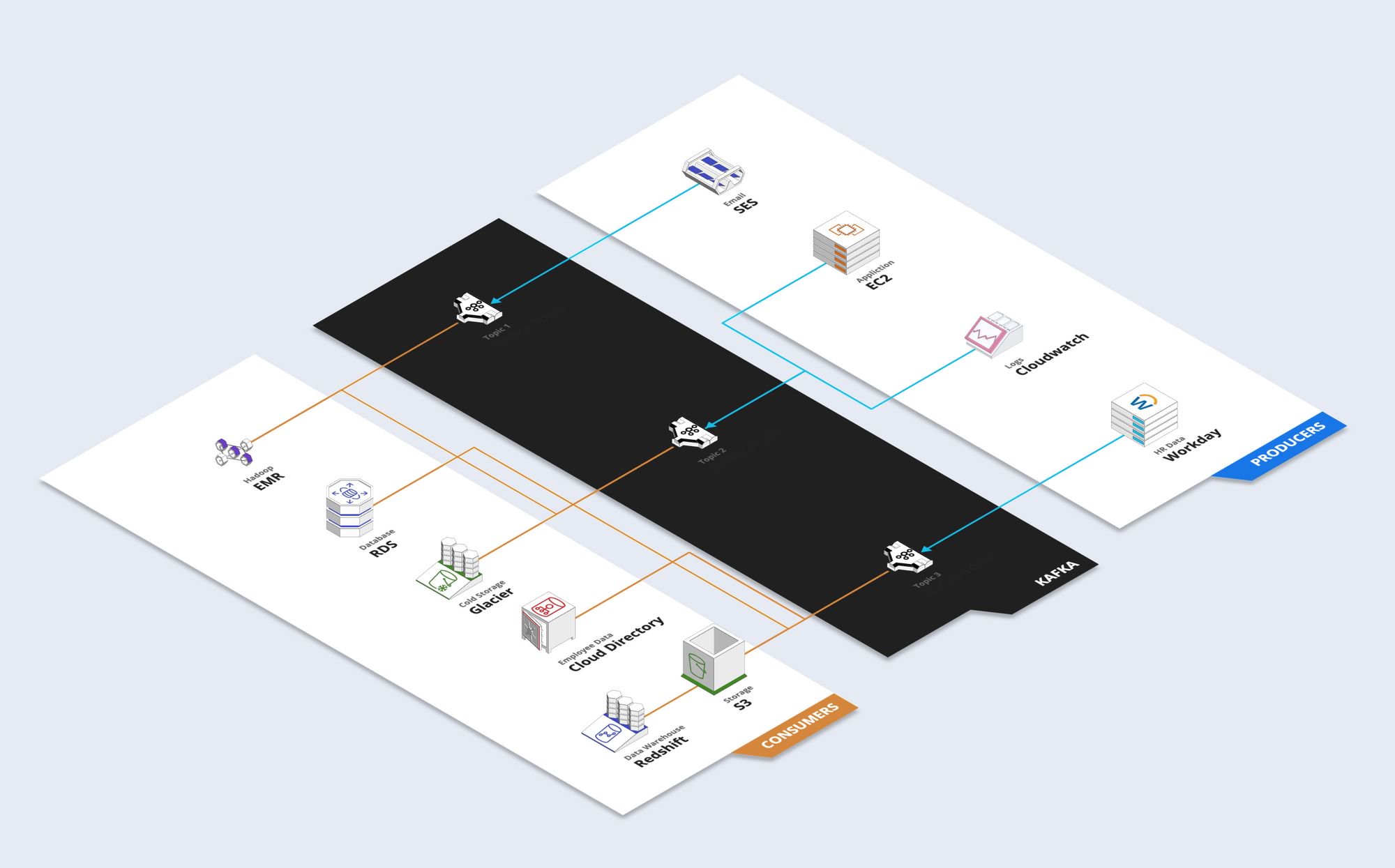
That's better. Now Kafka is in charge of our message queues (topics), which in some cases can consolidate information from different sources. We can also have Kafka handle notifications. For example, if we wanted to be notified of any fatal crashes from our Cloudwatch logs, we can set this up entirely in Kafka, and even have this trigger something like Pagerduty to hit us up while shit hits the fan.
Beneath the Hood of a Kafka Cluster
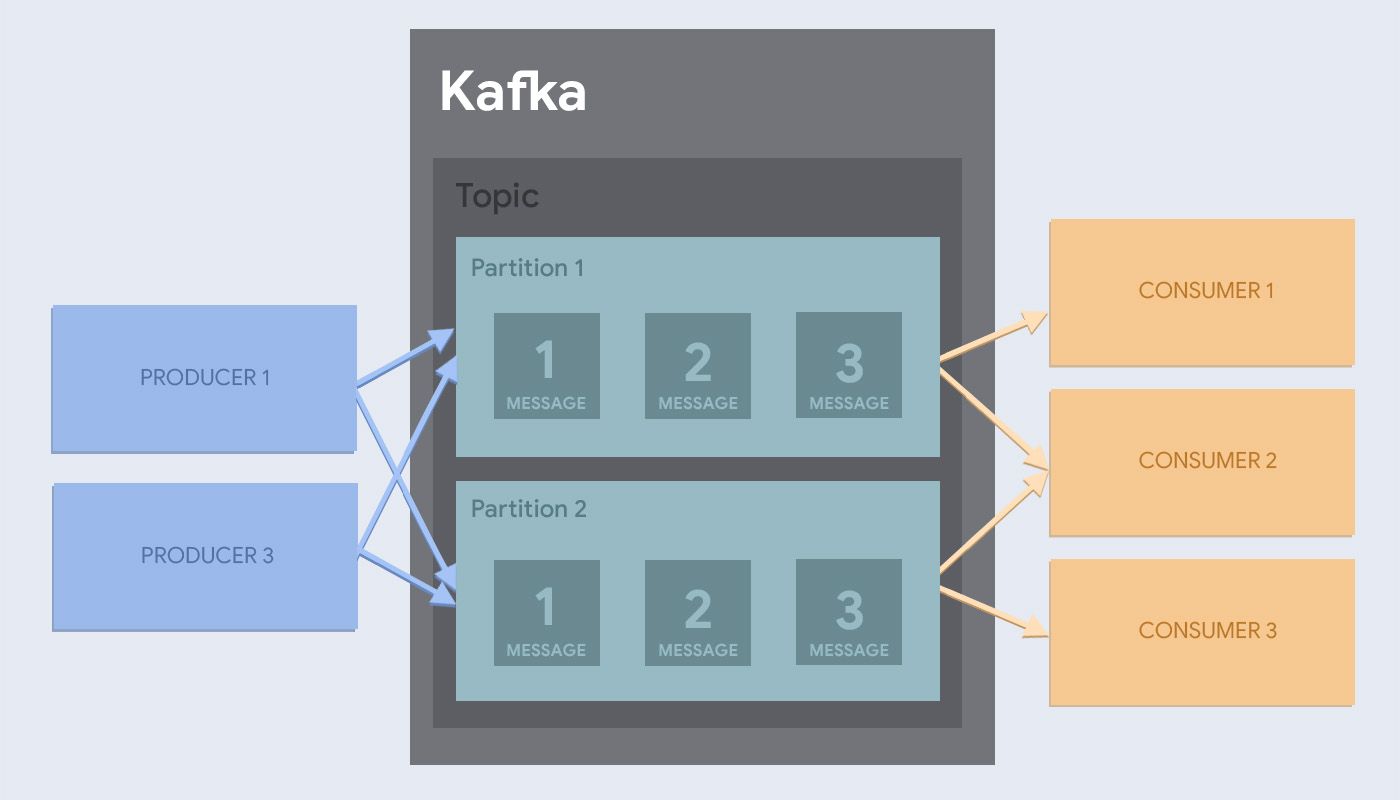
Like most things in the Hadoop ecosystem, a big strength of Kafka comes from its ability to scale across an infinite number of nodes in a cluster. Regardless of how the data load of your company changes, Kafka can handle adding nodes to its cluster to accommodate.
Scaling to multiple nodes works in Kafka by splitting topics across multiple partitions. When a topic is split into 2 partitions, that means the workload of a single topic is split across 2 nodes in the cluster. Therefore, we not only have the ability to dedicate nodes to topics, but we can split topics across multiple nodes if need be:
Options for Setting Up Kafka (or Equivalent)
There are a few options we have for setting up Kafka. Vanilla Kafka is not exactly a user-friendly setup, especially for anybody looking to set up multiple nodes in a cluster (AKA literally everybody), so it's worth considering which implementation suits your needs best, especially when taking your cloud provider into consideration.
Installing Kafka Manually
It's no fun, but anybody can set up a Kafka instance themselves by downloading the source and following these instructions. Kafka depends on Apache's Zookeeper as well, so there's a fair bit of setup required.
Kafka as a Service
If you're looking for the easiest way to get a Kafka instance up on a cloud provider, look no further than confluent.io. Like Databricks with Apache Spark, Confluent is a private company spun off by the original creator of Kafka (this is apparently a trend for people who donate software to the Apache Foundation). Confluent's paid offering is Confluent cloud: a managed Kafka instance with little configuration. Of course, it isn't cheap- the lower tier costs roughly 50 cents an hour, or 12ish bucks a day. This shouldn't be a surprise: the very nature of Kafka means it only makes sense to be used by businesses, thus almost any cloud Kafka provider will come with business pricing. Nobody is spinning up clusters of anything just for kicks.
The good news is Confluent also lets us download Confluent client for the local setup of a single-node instance. I personally prefer setting up Confluent over vanilla Kafka. For one, it's a bit easier to set up. Another great perk is the ability to implement Kafka Connect Datagen, which is a way for aspiring Kafka nerds to import dummy data into an instance, just in case we need help getting started.
Other Publisher/Subscriber offerings
Kafka isn't the only player in the game when it comes to messaging queues. There are plenty of stand-in alternatives to Kafka, many of which are easier to set up- especially if you're locked into a particular cloud provider. Here are some choice favorites:
- Amazon SQS: One of the oldest alternatives to Kafka. Runs into issues when throughput goes through the roof (like most AWS services... zing tbh).
- Amazon Kinesis: The closest thing AWS has to "Kafka as a service". Kinesis supports partitions like Kafka, as well as replicas.
- Google PubSub: A highly convenient alternative to Kafka. Perhaps one of the best options for anybody looking to hit the ground running, as there is no configuration needed. Can scale to massive volumes.
- RabbitMQ: A popular message broker, written in Erlang and similarly open-source. RabbitMQ plays well with almost every programming language imaginable.
The Future Is Unwritten
This is only the beginning of a long journey exploring the glorious wonders of message queues like Kafka. We have plenty more ground to cover, such as installation, configuration, and implementation. Don't touch that dial, we'll be right back with part 2!*
Feel free to touch that dial honestly, I don't feel like writing part 2 for a while.


