

If you have been following us from the beginning, you should have some working knowledge of loading data into PySpark data frames on Databricks and some useful operations for cleaning data frames like filter(), select(), dropna(), fillna(), isNull() and dropDuplicates() .
This time around, we'll be building on these concepts and introduce some new ways to transform data so you can officially be awarded your PySpark Guru Certification, award by us here at Hackers & Slackers.*
*Hackers & Slackers is not an accredited institution and is respected by virtually nobody in general.Loading Up Some Data
As usual, I'll be loading up some sample data from our best friend: Google BigQuery. The example data I'll be using is a public dataset from BigQuery: the results of the MLB 2016 postseason:
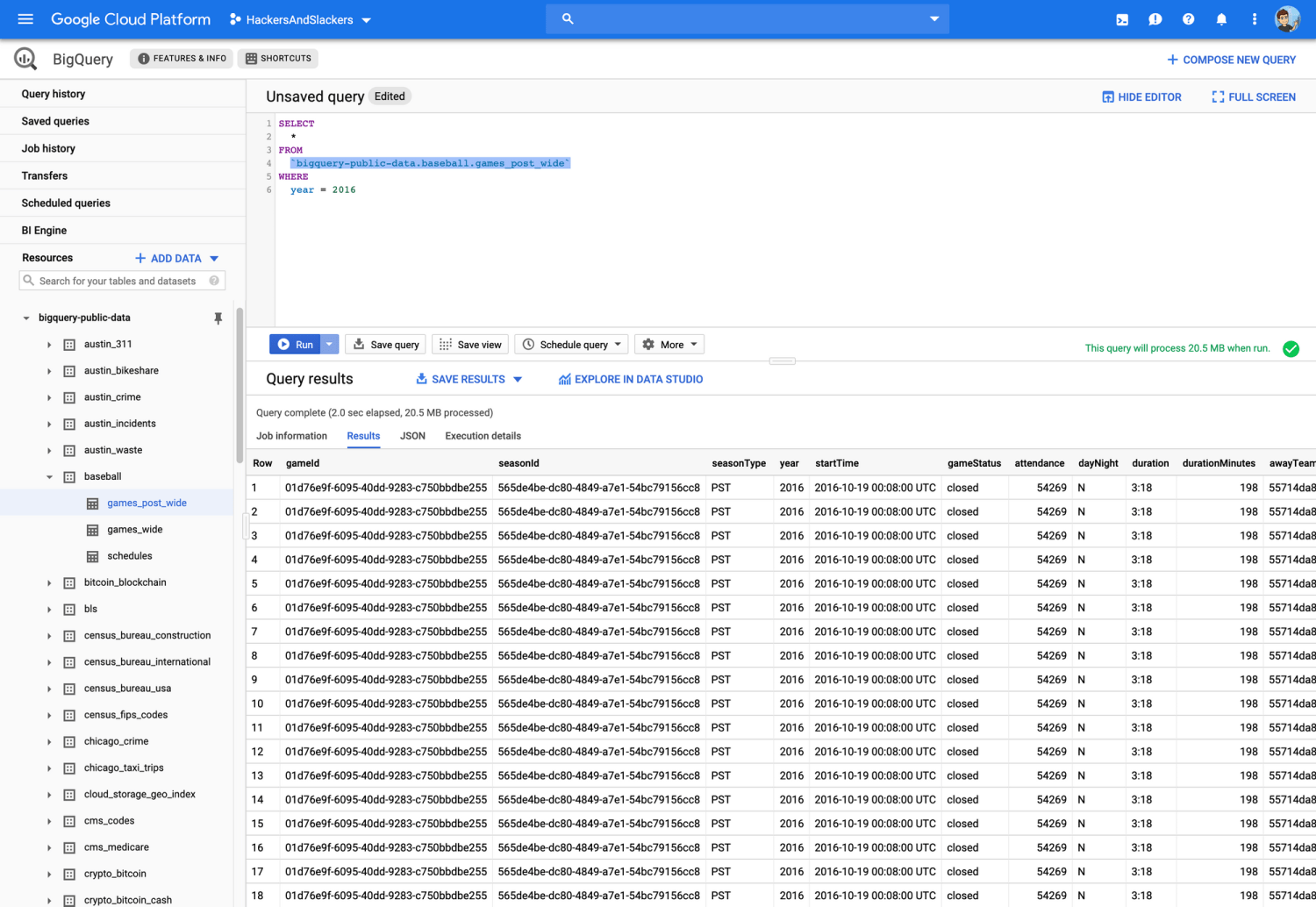
We'll export this data to a CSV. Next, we'll import this data into Databricks the same way as last time. Now we can get started messing with data.
For this exercise, we'll attempt to execute an elementary string of transformations to get a feel for what the middle portion of an ETL pipeline looks like (also known as the "transform" part 😁).
Simple Data Transformations
First things first, we need to load this data into a DataFrame:
# File location and type
file_location = "/FileStore/tables/results_20190428_181010-cc606.csv"
file_type = "csv"
# CSV options
infer_schema = "true"
first_row_is_header = "true"
delimiter = ","
# The applied options are for CSV files. For other file types, these will be ignored.
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
display(df)Nothing new so far! Of course, we should store this data as a table for future use:
# Create a view or table
permanent_table_name = "baseball_2016_postseason"
df.write.format("parquet").saveAsTable(permanent_table_name)Before going any further, we need to decide what we actually want to do with this data (I'd hope that under normal circumstances, this is the first thing we do)! Let's get a quick look at what we're working with, by using print(df.info()):
root
|-- gameId: string (nullable = true)
|-- seasonId: string (nullable = true)
|-- seasonType: string (nullable = true)
|-- year: integer (nullable = true)
|-- startTime: string (nullable = true)
|-- gameStatus: string (nullable = true)
|-- attendance: integer (nullable = true)
|-- dayNight: string (nullable = true)
|-- duration: string (nullable = true)
|-- durationMinutes: integer (nullable = true)
|-- awayTeamId: string (nullable = true)
|-- awayTeamName: string (nullable = true)
|-- homeTeamId: string (nullable = true)
|-- homeTeamName: string (nullable = true)
|-- venueId: string (nullable = true)
|-- venueName: string (nullable = true)
|-- venueSurface: string (nullable = true)
|-- venueCapacity: integer (nullable = true)
|-- venueCity: string (nullable = true)
|-- venueState: string (nullable = true)
|-- venueZip: integer (nullable = true)
|-- venueMarket: string (nullable = true)
...Holy hell, that's a lot of columns! Let's see what the deal is with these columns by inspecting our data via display(df):
| gameId | seasonId | seasonType | year | startTime | gameStatus | attendance | dayNight | duration | durationMinutes | awayTeamId | awayTeamName | homeTeamId | homeTeamName | venueId | venueName |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | 565de4be-dc80-4849-a7e1-54bc79156cc8 | PST | 2016 | 2016-10-19 00:08:00 UTC | closed | 54269 | N | 3:18 | 198 | 55714da8-fcaf-4574-8443-59bfb511a524 | Cubs | ef64da7f-cfaf-4300-87b0-9313386b977c | Dodgers | 66a19c3d-24fe-477d-bee7-c6ef1b98352f | Dodger Stadium |
You'll notice that there are multiple duplicates for gameId in our results. It turns out our dataset isn't just giving us the results of MLB games - it's giving us the result of every score in every game. That's a lot of data!
Let's say we only care about the outcome of entire games, as opposed to every score. That seems reasonable. First things first, let's rid ourselves of all these extra columns:
specific_columns_df = df.select(
"gameId",
"awayTeamName",
"homeTeamName",
"durationMinutes",
"homeFinalRuns",
"awayFinalRuns"
)
display(specific_columns_df)This will give us columns that are only relevant to entire games, as opposed to every score. But wait, we still have separate rows for every game! Let's make sure our dataset only has a single record per game:
dropped_df = specific_columns_df.dropDuplicates(subset = ['gameId'])
display(dropped_df)A quick comparison:
print('Original column count = ', specific_columns_df.count())
print('Dropped column count = ', dropped_df.count())Original column count = 8676
Dropped column count = 28We've gone from 8676 records to 28... which sounds more reasonable.
Adding and Modifying Columns
We can create new columns by calling withColumn() operation on a DataFrame, while passing the name of the new column (the first argument), as well as an operation for which values should live in each row of that column (second argument).
It's .lit() Fam
It's hard to mention columns without talking about PySpark's lit() function. lit() is simply one of those unsexy but critically important parts of PySpark that we need to understand, simply because PySpark is a Python API that interacts with a Java JVM (as you might be painfully aware).
lit() is a way for us to interact with column literals in PySpark: Java expects us to explicitly mention when we're trying to work with a column object. Because Python has no native way of doing it, we must instead use lit() to tell the JVM that what we're talking about is a column literal.
To import lit(), we need to import functions from pyspark.sql:
from pyspark.sql.functions import lit, when, colI've imported a few other things here which we'll get to later. With these imported, we can add new columns to a DataFrame the quick and dirty way:
from pyspark.sql.functions import lit, when, col, regexp_extract
df = df_with_winner.withColumn(
'testColumn',
F.lit('this is a test')
)
display(df)This will add a column, and populate each cell in that column with occurrences of the string: this is a test.
lit() is necessary when creating columns with values directly. If we use another function like concat(), there is no need to use lit() as it is implied that we're working with columns.Creating Columns Based on Criteria
Another function we imported with functions is the where function. PySpark's when() functions are kind of like SQL's WHERE clause (remember, we've imported this the from pyspark.sql package). In this case, we can use when() to create a column when the outcome of a conditional is true.
The first parameter we pass into when() is the conditional (or multiple conditionals, if you want). I'm not a huge fan of this syntax, but here's the format of this looks:
df = df.withColumn([COLUMN_NAME]. F.when([CONDITIONAL], [COLUMN_VALUE]))Let's use our baseball example to see the when() function in action. Remember last time when we added a "winner" column to our DataFrame? Well, we can do this using when() instead!
# Construct a new dynamic column
df = df_with_test_column.withColumn('game_winner', when(
(col("homeFinalRuns") > col("awayFinalRuns")), col("homeFinalRuns")
))Let's walk through this step by step, shall we? We set the name of our column to be game_winner off the bat. Next is the most important part: the conditional. In our example, we have (col("homeFinalRuns") > col("awayFinalRuns")). Remember how we said that The JVM we're interacting with absolutely must know which data type we're talking about at all times? col() means we're comparing the values of two columns; or more specifically, we're comparing the values in every row in these columns.
Also, notice that we don't specify something like df.col([COLUMN_NAME]), or even df.[COLUMN_NAME]. We instead pass a string containing the name of our columns to col(), and things just seem to work. PySpark is smart enough to assume that the columns we provide via col() (in the context of being in when()) refers to the columns of the DataFrame being acted on. After all, why wouldn't they? See... PySpark isn't annoying all the time - it's just inconsistently annoying (which may be even more annoying to the aspiring Sparker, admittedly).
But wait, something's missing! We've only added the winner when the winner happens to be the home team! How do we add the away team? Is there some sort of else equivalent to when()? Why yes, I'm so glad you've asked! It happens to be called otherwise().
With otherwise(), we can tack on an action to take when conditional in our when() statement returns False! That means our when() statement now takes this shape:
df = df.withColumn([COLUMN_NAME]. F.when([CONDITIONAL], [COLUMN_VALUE]).otherwsie([COLUMN_VALUE]))Now modifying our original snippet:
# Construct a new dynamic column
df = df_with_test_column.withColumn('gameWinner', when(
(col("homeFinalRuns") > col("awayFinalRuns")), col("homeFinalRuns")
).otherwise(lit('awayTeamName')))
display(df)Excellent, dear boy and/or girl! Let's get a look at what we've done so far:
| awayTeamName | homeTeamName | homeFinalRuns | awayFinalRuns | durationMinutes | testColumn | gameWinner |
|---|---|---|---|---|---|---|
| Red Sox | Indians | 6 | 0 | 199 | this is a test | Indians |
| Nationals | Dodgers | 3 | 8 | 252 | this is a test | Nationals |
| Orioles | Blue Jays | 5 | 2 | 205 | this is a test | Blue Jays |
| Dodgers | Nationals | 3 | 4 | 272 | this is a test | Dodgers |
| Cubs | Dodgers | 2 | 10 | 238 | this is a test | Cubs |
| Indians | Red Sox | 3 | 4 | 221 | this is a test | Indians |
| Red Sox | Indians | 5 | 4 | 213 | this is a test | Indians |
| Nationals | Dodgers | 6 | 5 | 224 | this is a test | Dodgers |
| Blue Jays | Rangers | 3 | 5 | 210 | this is a test | Blue Jays |
| Rangers | Blue Jays | 7 | 6 | 201 | this is a test | Blue Jays |
| Giants | Cubs | 1 | 0 | 150 | this is a test | Cubs |
| Dodgers | Cubs | 0 | 1 | 165 | this is a test | Dodgers |
| Cubs | Dodgers | 6 | 0 | 198 | this is a test | Dodgers |
| Dodgers | Cubs | 5 | 0 | 156 | this is a test | Cubs |
| Giants | Mets | 0 | 3 | 191 | this is a test | Giants |
| Cubs | Giants | 6 | 5 | 303 | this is a test | Giants |
| Dodgers | Cubs | 8 | 4 | 217 | this is a test | Cubs |
| Blue Jays | Indians | 2 | 1 | 164 | this is a test | Indians |
| Indians | Blue Jays | 5 | 1 | 181 | this is a test | Blue Jays |
| Cubs | Giants | 5 | 6 | 205 | this is a test | Cubs |
| Blue Jays | Rangers | 1 | 10 | 178 | this is a test | Blue Jays |
| Blue Jays | Indians | 2 | 0 | 164 | this is a test | Indians |
| Cubs | Dodgers | 4 | 8 | 256 | this is a test | Cubs |
| Dodgers | Nationals | 3 | 4 | 226 | this is a test | Dodgers |
| Giants | Cubs | 5 | 2 | 183 | this is a test | Cubs |
| Indians | Blue Jays | 0 | 3 | 157 | this is a test | Indians |
| Dodgers | Nationals | 5 | 2 | 235 | this is a test | Nationals |
| Indians | Blue Jays | 2 | 4 | 203 | this is a test | Indians |
So far so good, but maybe we should get rid of that useless testColumn we created?
Dropping Entire Columns
Dropping columns is easy! we can simply use the drop() method on our DataFrame, and pass the name of the column:
df = df_with_test_column.drop('testColumn')That does the trick! Feel free to check by using display(df).
String Operations & Filters
We've looked at how filter() works pretty extensively. Why don't we pair this with some of Spark's common string operations to see how powerful filtering can be?
like() and related operators
The PySpark like() method works exactly like the SQL equivalent: % denotes a wild card, meaning "any character or number of characters". Take a look at how we'd use like() to find winning teams whose names start with "Nat":
df = df.filter(df.winner.like('Nat%'))
display(df)| awayTeamName | homeTeamName | durationMinutes | homeFinalRuns | awayFinalRuns | winner |
|---|---|---|---|---|---|
| Nationals | Dodgers | 252 | 3 | 8 | Nationals |
| Dodgers | Nationals | 235 | 5 | 2 | Nationals |
Wow, the Nationals only won two games! Hah, they sure do suck. Sorry about Harper, by the way.
like() covers a lot. We can use like() to see if a string contains, starts with, or ends with a value. I highly recommend using like() where possible, but if that's not your cup of tea, you can use contains(), startswith(), and endsWith() instead. They all do what you'd imagine.
isIn() to Match Multiple Values
If we want to match by multiple values, isIn() is pretty great. This takes multiple values as its parameters, and will return all rows where the columns of column X match any of n values:
df = df.filter(df.gameWinner.isin('Cubs', 'Indians'))
display(df)gameWinner contains either "Indians" or "Cubs"| awayTeamName | homeTeamName | durationMinutes | homeFinalRuns | awayFinalRuns | gameWinner |
|---|---|---|---|---|---|
| Red Sox | Indians | 199 | 6 | 0 | Indians |
| Indians | Red Sox | 221 | 3 | 4 | Indians |
| Red Sox | Indians | 213 | 5 | 4 | Indians |
| Giants | Cubs | 150 | 1 | 0 | Cubs |
| Dodgers | Cubs | 156 | 5 | 0 | Cubs |
| Dodgers | Cubs | 217 | 8 | 4 | Cubs |
| Blue Jays | Indians | 164 | 2 | 1 | Indians |
| Cubs | Giants | 205 | 5 | 6 | Cubs |
| Blue Jays | Indians | 164 | 2 | 0 | Indians |
| Cubs | Dodgers | 256 | 4 | 8 | Cubs |
| Giants | Cubs | 183 | 5 | 2 | Cubs |
| Indians | Blue Jays | 157 | 0 | 3 | Indians |
| Indians | Blue Jays | 203 | 2 | 4 | Indians |
concat() For Appending Strings
Here's another SQL sweetheart. Using concat() adds strings together:
df = df.withColumn(
"gameTitle",
concat(df.homeTeamName, lit(" vs. "), df.awayTeamName)
)
display(df)| awayTeamName | homeTeamName | homeFinalRuns | awayFinalRuns | durationMinutes | winner | gameTitle |
|---|---|---|---|---|---|---|
| Red Sox | Indians | 6 | 0 | 199 | Indians | Indians vs. Red Sox |
| Nationals | Dodgers | 3 | 8 | 252 | Nationals | Dodgers vs. Nationals |
| Orioles | Blue Jays | 5 | 2 | 205 | Blue Jays | Blue Jays vs. Orioles |
| Dodgers | Nationals | 3 | 4 | 272 | Dodgers | Nationals vs. Dodgers |
| Cubs | Dodgers | 2 | 10 | 238 | Dodgers | Dodgers vs. Cubs |
| Indians | Red Sox | 3 | 4 | 221 | Indians | Red Sox vs. Indians |
| Red Sox | Indians | 5 | 4 | 213 | Indians | Indians vs. Red Sox |
| Nationals | Dodgers | 6 | 5 | 224 | Dodgers | Dodgers vs. Nationals |
| Blue Jays | Rangers | 3 | 5 | 210 | Blue Jays | Rangers vs. Blue Jays |
| Rangers | Blue Jays | 7 | 6 | 201 | Blue Jays | Blue Jays vs. Rangers |
| Giants | Cubs | 1 | 0 | 150 | Cubs | Cubs vs. Giants |
| Dodgers | Cubs | 0 | 1 | 165 | Dodgers | Cubs vs. Dodgers |
| Cubs | Dodgers | 6 | 0 | 198 | Dodgers | Dodgers vs. Cubs |
| Dodgers | Cubs | 5 | 0 | 156 | Cubs | Cubs vs. Dodgers |
| Giants | Mets | 0 | 3 | 191 | Giants | Mets vs. Giants |
| Cubs | Giants | 6 | 5 | 303 | Giants | Giants vs. Cubs |
| Dodgers | Cubs | 8 | 4 | 217 | Cubs | Cubs vs. Dodgers |
| Blue Jays | Indians | 2 | 1 | 164 | Indians | Indians vs. Blue Jays |
| Indians | Blue Jays | 5 | 1 | 181 | Blue Jays | Blue Jays vs. Indians |
| Cubs | Giants | 5 | 6 | 205 | Cubs | Giants vs. Cubs |
| Blue Jays | Rangers | 1 | 10 | 178 | Blue Jays | Rangers vs. Blue Jays |
| Blue Jays | Indians | 2 | 0 | 164 | Indians | Indians vs. Blue Jays |
| Cubs | Dodgers | 4 | 8 | 256 | Cubs | Dodgers vs. Cubs |
| Dodgers | Nationals | 3 | 4 | 226 | Dodgers | Nationals vs. Dodgers |
| Giants | Cubs | 5 | 2 | 183 | Cubs | Cubs vs. Giants |
| Indians | Blue Jays | 0 | 3 | 157 | Indians | Blue Jays vs. Indians |
| Dodgers | Nationals | 5 | 2 | 235 | Nationals | Nationals vs. Dodgers |
| Indians | Blue Jays | 2 | 4 | 203 | Indians | Blue Jays vs. Indians |
.regexp_extract() for Regex Functions
For real programmers who know what they're actually doing, you can disregard all those other lame string operations: regexp_extract() is the moment you've been waiting for. This takes one parameter: your regex. I could totally demonstrate my 1337 regex skills right here, but uh, I just don't feel like it right now:
df = df.withColumn(
"newColumn",
regexp_extract([INSERT_1337_REGEX_HERE])
)
Number Operators
You should be getting the point by now! Here are some number operators, which you can use just like the string operators (speaking syntactically, which is apparently a word):
round: Rounds to the nearest scale. Accepts a column as the first parameter, and a scale as the second.floor: Returns the lowest number in a set. Accepts a column name as the first parameter.ceil: Returns the highest number in a set. Accepts a column name as the first parameter.
User-Defined Functions
What if we want to transform our data in a less predictable way, like by creating our own customizations? Is that so much to ask? It isn't, but it's significantly more difficult/convoluted than, say, Pandas. Optimizing code for speed at runtime sure is a bitch.
Custom transformations in PySpark can happen via User-Defined Functions (also known as UDFs). As you may imagine, a user-defined function is just a function we create ourselves and apply to our DataFrame (think of Pandas' .apply()).
To user UDFs, we need to import udf from pyspark.sql.functions, as well as any other imports we'll be using within that UDF. Furthermore, we'll need to import the type of data we're expecting to be returned from our function:
from pyspark.sql.functions import udf, array
from pyspark.sql.types import StringTypeWe're importing array because we're going to compare two values in an array we pass, with value 1 being the value in our DataFrame's homeFinalRuns column, and value 2 being awayFinalRuns. We're also importing StringType, because we'll be returning the name of the team which wins:
from pyspark.sql.functions import udf, array
from pyspark.sql.types import StringType
determine_winner_udf = udf(
lambda arr: arr[2] if arr[0] > arr[1] else arr[3],
StringType()
)
df_with_winner = dropped_df.withColumn(
"winner",
determine_winner_udf(array(
"homeFinalRuns",
"awayFinalRuns",
"homeTeamName",
"awayTeamName")
)
)
display(df_with_winner)It isn't beautiful, but it gets the job done. For each row in our DataFrame, we pass 4 values:
- The home team score.
- The away team score.
- The home team name.
- The away team name.
Our UDF, determine_winner_udf, determines a winner from the first two array values. Depending on who wins, our lambda returns the home team name (arr[2]) or the away team name (arr[3]).
Let's see what we've got:
| gameId | awayTeamName | homeTeamName | durationMinutes | homeFinalRuns | awayFinalRuns | winner |
|---|---|---|---|---|---|---|
| 15557732-6fbb-481f-9e14-928b33c4e1e3 | Red Sox | Indians | 199 | 6 | 0 | Indians |
| 0e8fb2a4-93f4-4642-b463-f1df0a860a85 | Nationals | Dodgers | 252 | 3 | 8 | Nationals |
| c7c45139-0266-48de-93b3-d9b589961112 | Orioles | Blue Jays | 205 | 5 | 2 | Blue Jays |
| bac7845d-32ae-4202-b21f-84af42bfb092 | Dodgers | Nationals | 272 | 3 | 4 | Dodgers |
| 877def36-ec67-41ee-9261-2fd268f9900d | Cubs | Dodgers | 238 | 2 | 10 | Dodgers |
| 7910731d-d014-44d9-b1ea-68c6caf4e78b | Indians | Red Sox | 221 | 3 | 4 | Indians |
| c6949116-bd88-4b54-959d-46794a55a4b1 | Red Sox | Indians | 213 | 5 | 4 | Indians |
| 681dd595-cd0f-440f-b9ac-746dffa9f776 | Nationals | Dodgers | 224 | 6 | 5 | Dodgers |
| d0992c0e-f771-4da5-be4e-42a8568f7c50 | Blue Jays | Rangers | 210 | 3 | 5 | Blue Jays |
| 6d62f75d-2021-46d8-8c8c-f27006914cff | Rangers | Blue Jays | 201 | 7 | 6 | Blue Jays |
| 892f4258-cfcf-45ef-b8eb-c91a122b9699 | Giants | Cubs | 150 | 1 | 0 | Cubs |
| 9dc592e4-a5c8-4222-a48e-d518053244d6 | Dodgers | Cubs | 165 | 0 | 1 | Dodgers |
| 01d76e9f-6095-40dd-9283-c750bbdbe255 | Cubs | Dodgers | 198 | 6 | 0 | Dodgers |
| 1a39d635-16f2-4b4d-844c-d63c56255a3d | Dodgers | Cubs | 156 | 5 | 0 | Cubs |
| 0428cd83-266b-4e17-8dae-096d7c6d4416 | Giants | Mets | 191 | 0 | 3 | Giants |
Visualizing the Results
It seems like we've got what we wanted! We now have a dataset that can tell us the winningest team in the 2016 post-season (kind of: we're using a limited dataset, but whatever). How can we visualize this data? Why, with the Databricks built-in plot options, of course! Each time we use display() to show our DataFrame, we can modify the plot options to show us a chart representing our data, as opposed to a table:
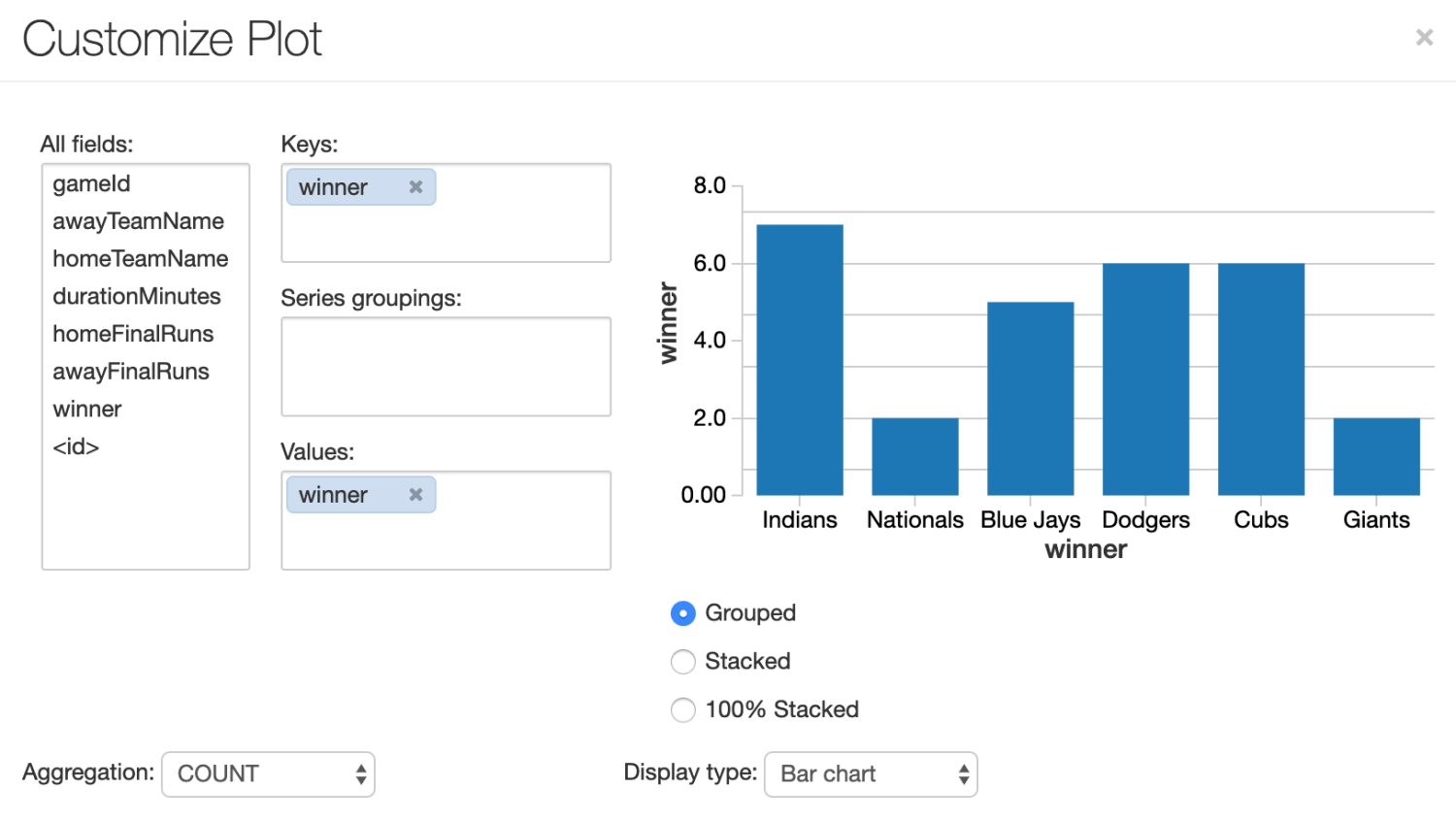
From the chart-looking dropdown, select bar chart. Next, check out the plot options button which results in this modal:
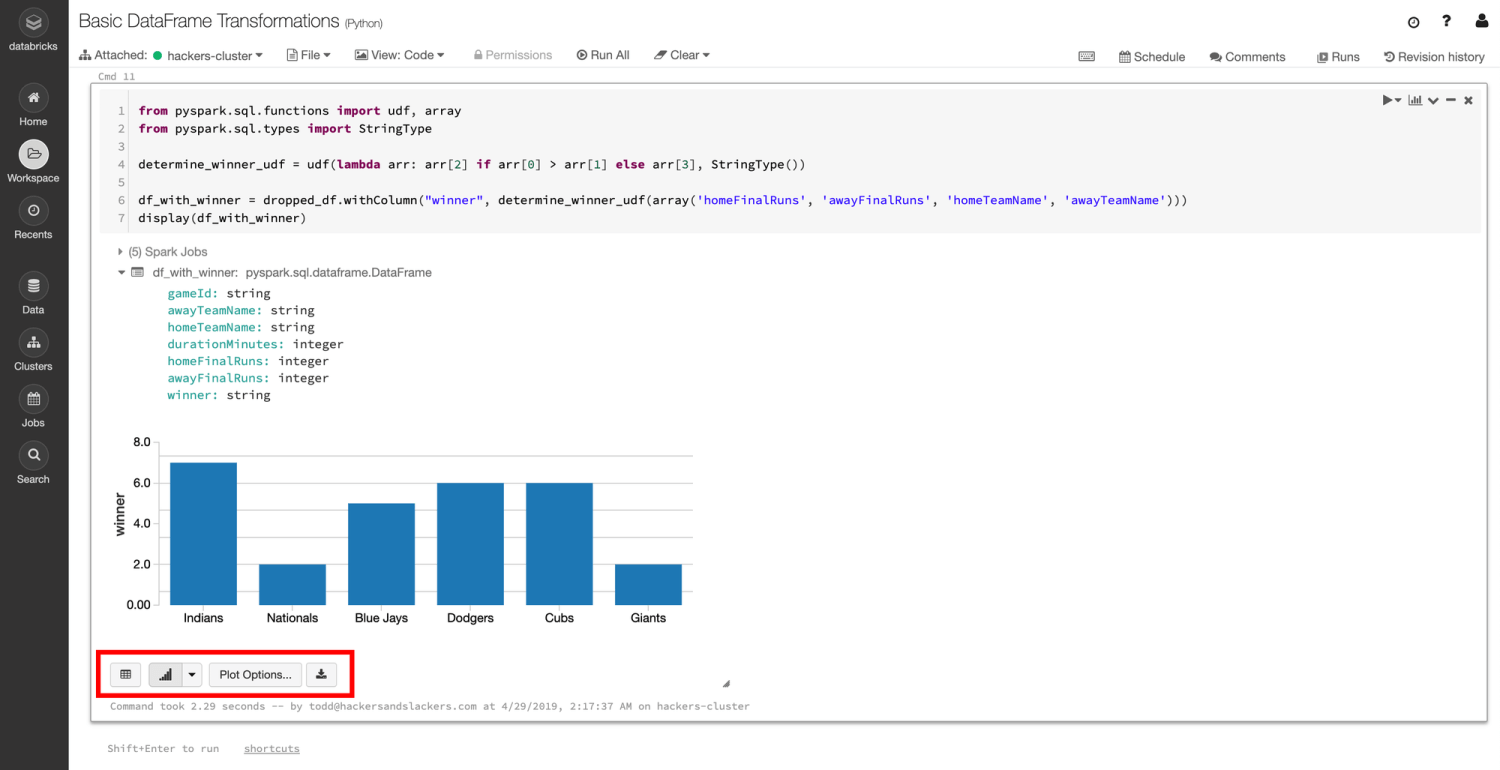
I've messed with the settings to show us a distribution of wins above. We aggregate by COUNT, thus counting the number of instances where the winner column contains each of the team names involved.
A Moment of Reflection
You've done great, young Padawan. We took a real-life instance of some data we wanted to change, and we changed it: all in PySpark.
As you've probably noticed, working with PySpark isn't at all like working in pure-Python alternatives for modifying data. Sure, we're writing code in Python, but as we implement explicit type-setting and navigate user-defined functions, it becomes painfully evident that we're using an API that hooks into a Java application. On the bright side, we've built a respectable string of transformations that can occur across multiple nodes without writing a single line of Scala (or worse yet, Java).
When we consider the scalability, speed, and power of what we've just built, the little quirks don't seem so bad anymore.



