
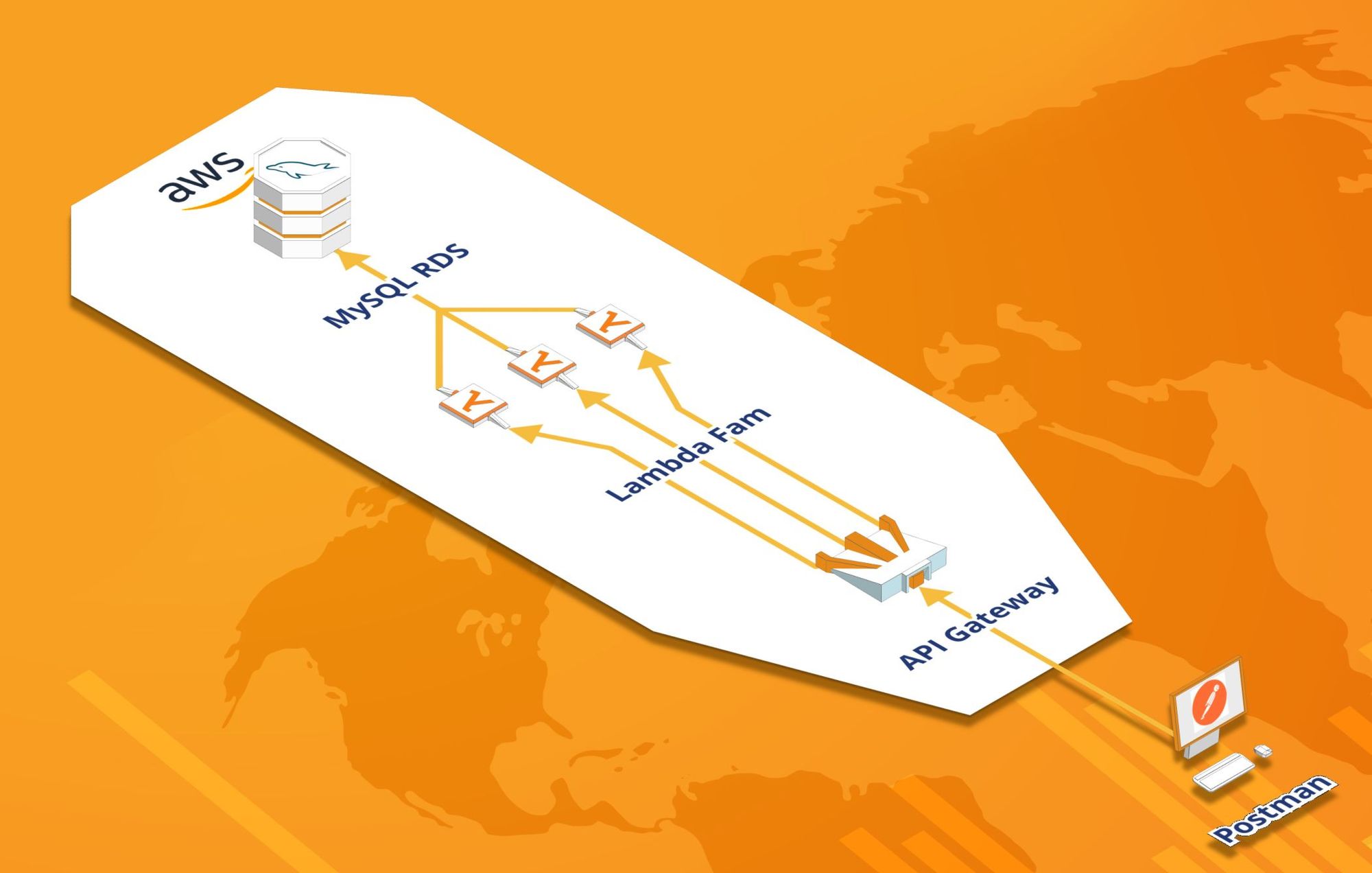
In our last adventure, we ventured off to create our very own cloud database by using Amazon's RDS service. We've also briefly covered the general concept behind what Lambda functions. In case you've already forgotten, Lambdas are basically just chunks of code in the cloud; think of them as tiny virtual servers, which have already been configured (and locked down) to serve one specific purpose. Because that's literally what it is.
The data being stored in RDS is ultimately what we're targeting, and Lambdas serve as the in-between logic to serve up, modify, or add to the proper data. The only piece missing from the picture is API Gateway.
As the name suggests, API Gateway is the, uh, gateway that users or systems interact with to obtain what they're seeking. It is (hopefully) the only part of this VPC structure an external user can interact with:
Serving as a "gateway" is obviously what all APIs so, but the term is also true in the sense that API Gateway is completely configured via UI, thus engineers of any programming background can safely modify endpoints, methods, CORs configurations, or any of the high-level API structure without being locked into a programming language. API Gateway is therefore very much an enterprise-geared product: it lends itself to large teams and scaling. That said, if it were to be compared to building an API via a framework designed to do such things (such as Express or Flask) the experience is undoubtedly more clunky. The trade-off being made for speed is immediate visibility, assurance, and a higher chance for collaboration.
The Challenge of Building a "Well-Designed" API
Good APIs are premeditated. A complex API might accept multiple methods per endpoint, allow advanced filtering of results, or handle advanced Authentication. Neither of us have the time to attempt covering all of those things in detail, but I will leave you with the knowledge that all these features are very much possible.
The API Gateway interface is where you'd get started. Let's blow through the world's most inappropriately fast explanation of building APIs ever ,and check out the UI:
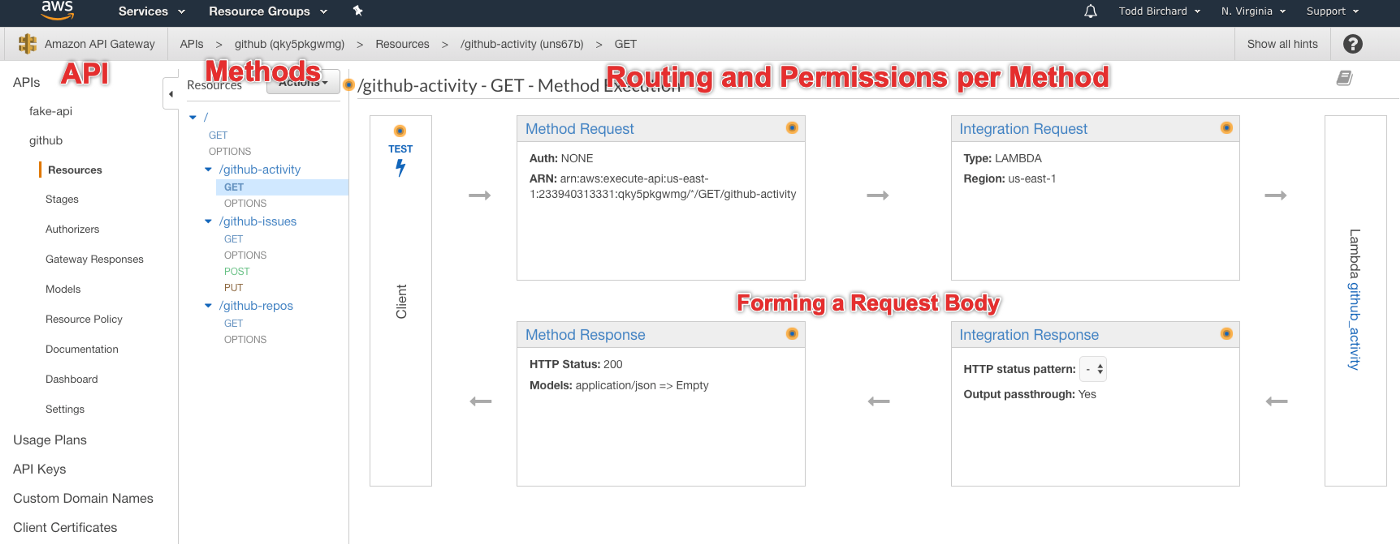
- Your APIs are listed on the left. You can create more than one, if you're some sort of sadist.
- The Resources pane is the full structure of your API. At the highest level, 'resources' refers to Endpoints, which are the URLs your API will ultimately expose.
- Every Endpoint can contain whichever Methods you choose to associate with them (GET, POST, PUT, etc). Even if they belong to the same endpoint, a POST method could contain entirely unrelated logic from a PUT method: its your responsibility to make sure your API design makes sense.
- Finally, each Method has their expected Request and Response structures defined individually, which what the horribly designed box diagram is attempting to explain on the right. The box on the left labeled CLIENT refers to the requester, where the box on the right represents the triggered action.
This UI is your bread and butter. I hope you're strapped in, because walking through this interface is going to be hella boring for all of us.
Creating a Method Request
The first step to creating an endpoint (let's say a GET endpoint) is to set the expectation for what the user will send to us:
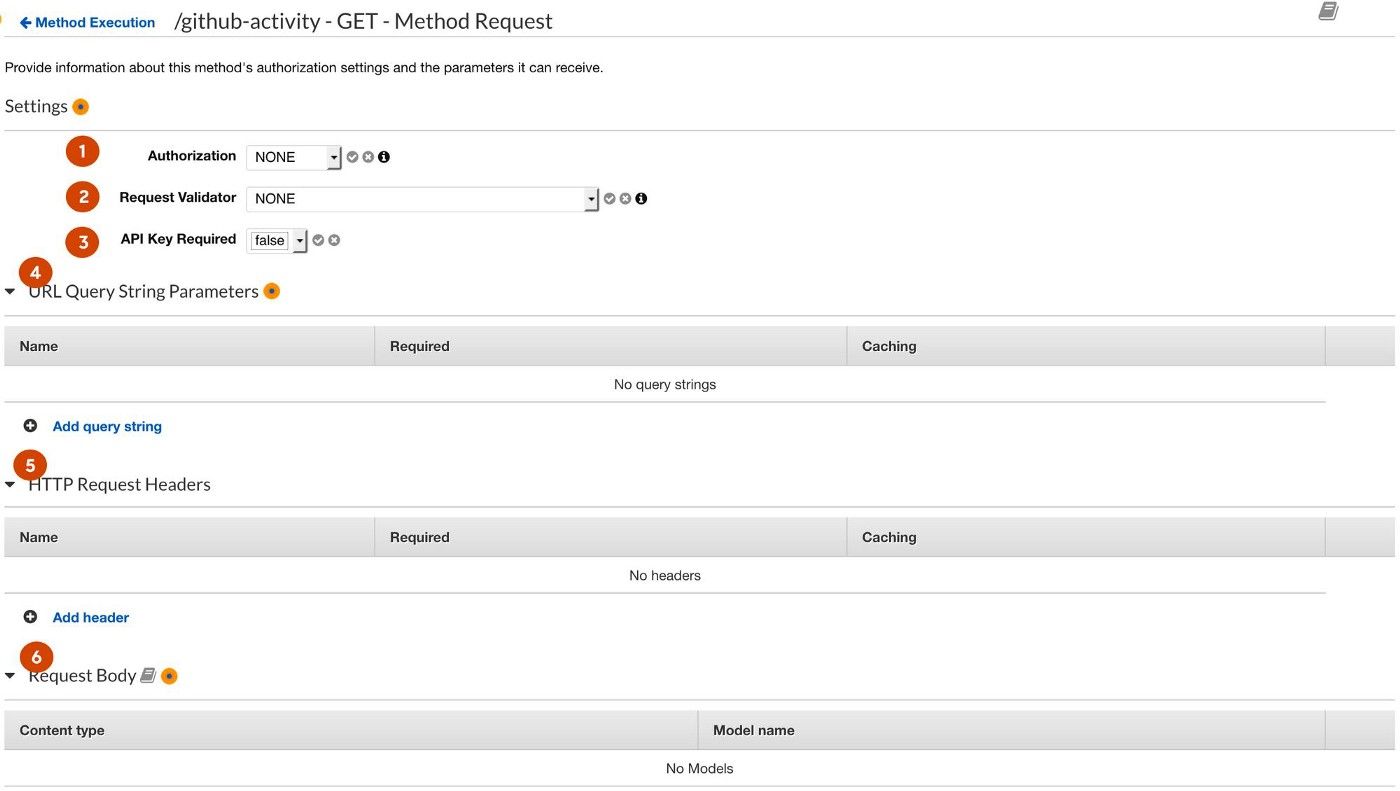
- Authorization allows you to restrict users from using your API unless they follow your IAM policy.
- Request Validator lets you chose if you'd like this validation to happen via the body, query string parameters, headers, or all of the above.
- API Keys are useful if you're creating an API to sell commercially or enforce limited access. If your business model revolves around selling an API, you can realistically do this.
- Query String Parameters are... actually forget it, you know this by now.
- See above.
- If preferred, the Request Body can be assigned a model, which is essentially a JSON schema. If a request is made to your endpoint which does not match the request body model, it is a malformed request. We'll cover models in the advanced course, once somebody actually starts paying me to write this stuff.
Method Execution: AKA "What do we do with this?"
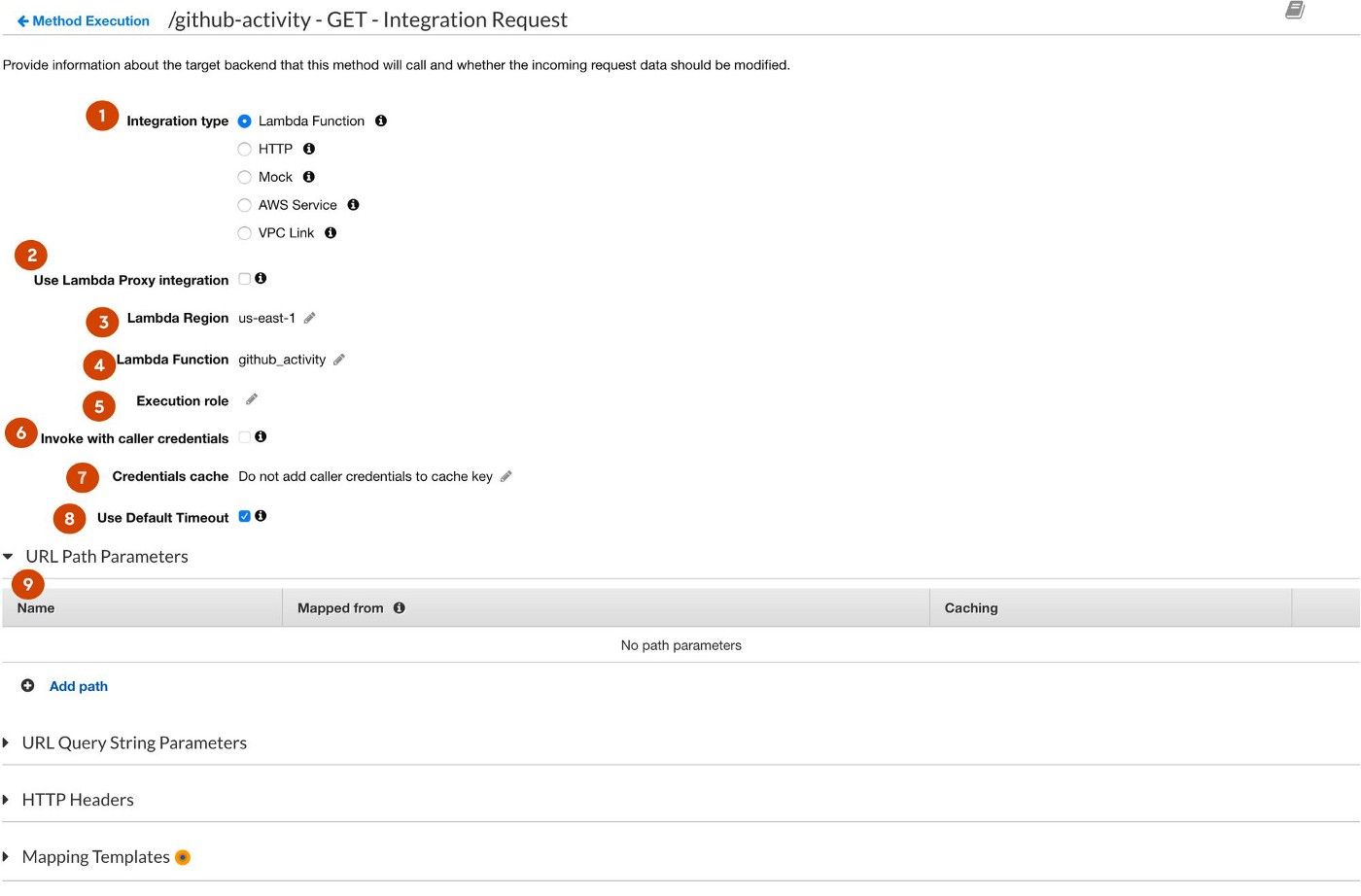
- Integration Type specifies which AWS service will be accepting or affected by this request. The vast majority of the time, this will be Lambda. If you're wondering why other AWS Services aren't present, this has been made intentional over time as just about any AWS service you can interact with will still need logic to do anything useful: you can't just shove a JSON object in a database's face and expect to get results. Unless you're using MongoDB or something.
- Lambda Proxies are generally a bad idea. They auto-format your Lambda's request and response body to follow a very specific structure, which is presumably intended to help speed up or standardize development. The downside is these structures are bloated and most likely contain useless information. To get an idea of what these structures look like, check them out here.
- The Region your Lambda hosted lives in.
- Name of the Lamba Function your request will be directed to.
- Execution role refers to the IAM role your Lambda policy will be a part of. This is kind of an obnoxious concept, but your function has permissions as though it were a user. This is presumably Amazon's way of thinking ahead to extending human rights to robots.
- Caller Credentials refers to API keys, assuming you chose to use them. If this is checked, the API will not be usable without an API key, thus making it difficult to test
- Credentials Cache probably refers to expiring credentials or something, I'm sure you'll figure it out.
- Timeout can be increased if you're dealing with an API call that takes a lot of time to respond, such as occasions with heavy data sets.
- URL Paths probably do something, I don't know. Who really cares?
INTERMISSION: The Part Where Things Happen
The next step in the flow would be where the AWS service we selected to handle the request would do its thing. We'll get into that next time.
Response Codes and Headers
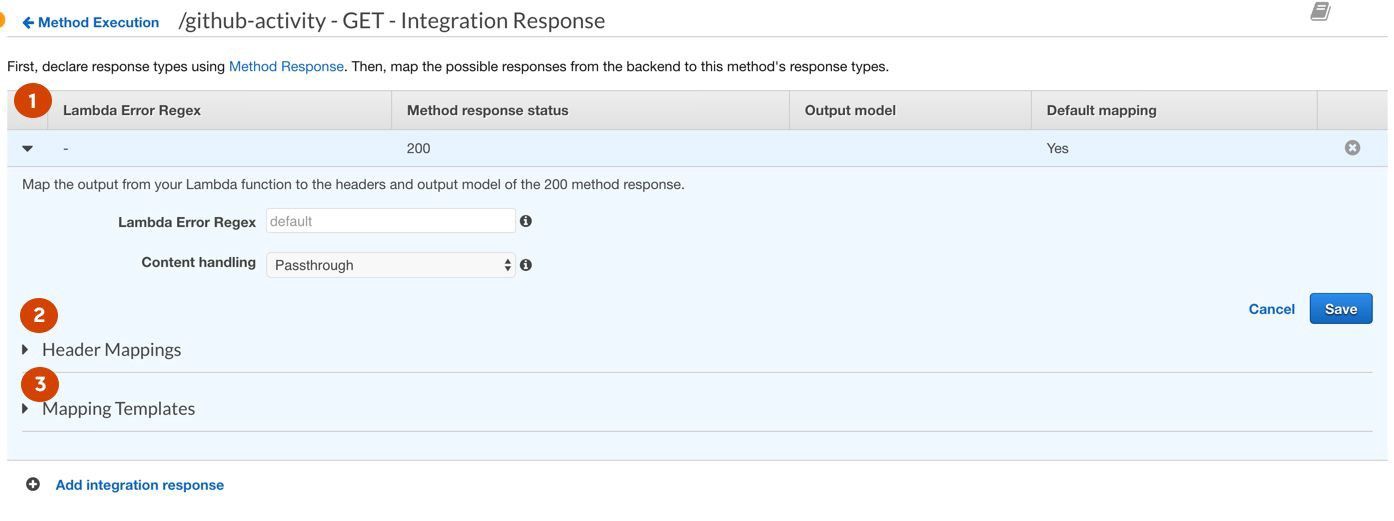
- While AWS provides users with standard error codes and generic errors, you can add your own specific error/success messages. Props to whoever puts in the effort.
- Header Mappings are the headings returned with the response. For example, this is where you might solve cross-domain issues via the Access-Control-Allow-Origin header.
- Mapping Templates are the Content-Type of the response returned, most commonly application/json.
Method Response
This step is a continuation of the previous step. I'm not entirely sure what the point in splitting this into two screens is, but I'm guessing its not important.
Reap Your Rewards
At long last, this brings us to the end of our journey. This is presumably where you've executed a successful AWS test or something. However, there's a final step before you go live; deploying your API:
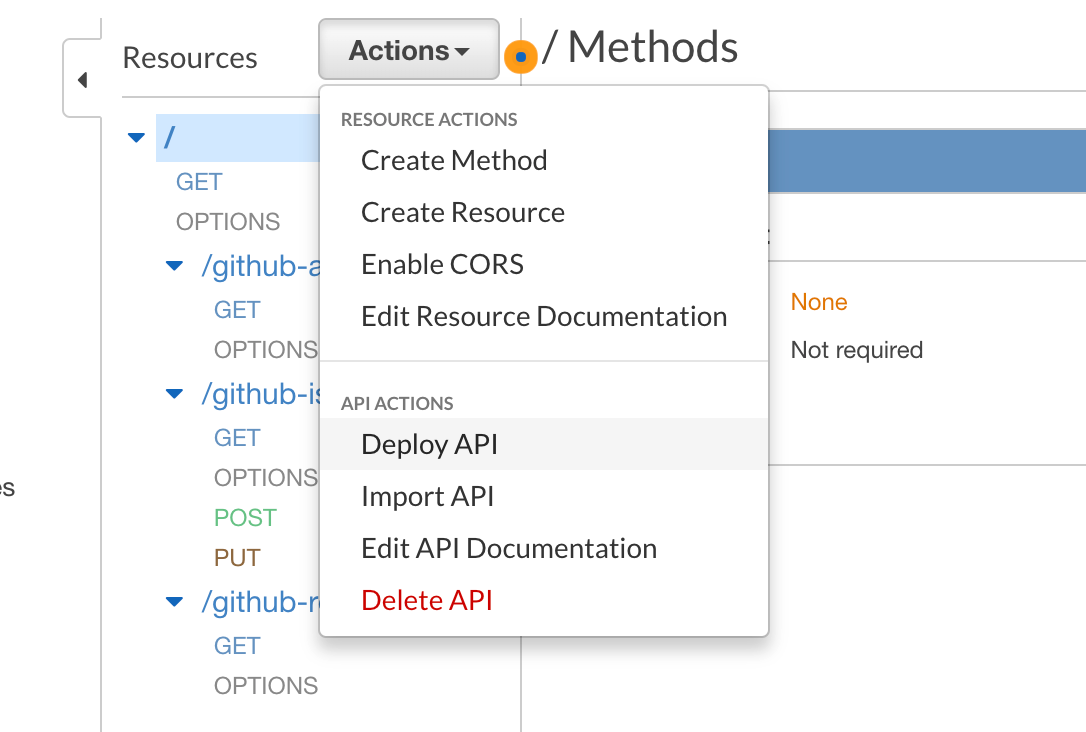
Next time we'll cover the logical, less boring part of writing actual code behind these endpoints.



